NVIDIA RTX Spark発表:統合メモリとCUDAで個人PCの新時代を切り開く
PCの新時代:NVIDIA GTC Taipei 2026
NVIDIA GTC Taipei 2026が、現地時間午前11時に開幕した。数多くの発表があった中で、個人的に最も歴史的意義を持つと感じた製品がある。それほどのものだからこそ、NVIDIAは「パーソナルコンピュータ誕生40周年を迎え、今回、再定義する」と宣言している。
「A New Line, A New Beginning」
そのすべては、一つの全新たな消費者向けチップ——長らくリークされていたコードネーム「N1X」のRTX Spark——から始まる。

この小さなデバイスこそが、今年上半期で最も期待していたAIカンファレンスの核心だ。この時代に、複数の大手企業が連携して事前に熱を上げ、一つの発表会にすべてを注ぎ込む姿は滅多に見られない。
PCの新時代。これほどの布陣を組めるのは、NVIDIAくらいのものだろう。奇妙に見える一連の数字は、ジェンスン・ハンの基調講演が行われた台北ポップミュージックセンターの座標である。
本日の発表を見終わった今、「パーソナルPCの新時代」という言葉を信じずにはいられない。
今年上半期のAIの進展は、OpenClaw、Claude Code、Codexなど、すべてがクラウド上の大規模モデルだった。しかしコンシューマー向けのハードウェア層では、ほとんど進展がなかった。だが、大規模モデルやAgentをローカル環境に展開したいという欲求は誰にでもある。低レイテンシ、プライバシー保護、ネットワーク不要。推論だけでなくファインチューニングまで行える自由で安全な感覚は、常に人を魅了し続ける。
新しいハードウェアが必要だ。新しいチップが必要だ。そして、もっと面白い想像力が必要だ。その期待がことごとく今回のNVIDIA GTC Taipei 2026に注がれていた。そして、RTX Sparkは待ちに待った形で登場した。

NVIDIAやゲームに詳しい読者なら、RTXとSparkという二つの単語はそれぞれ馴染み深いだろう。RTXはNVIDIAの消費者向け製品ラインであり、RTX 5080などのグラフィックスカードとして最も身近に存在する。Sparkは、昨年発表された開発者向けDGX Sparkに由来するが、今回正式にNVIDIAの全新たな事業ラインとして昇華した。こうしてRTX Sparkが誕生した。
RTX Sparkのスペックと可能性
RTX Sparkのベースは、DGX Sparkと同じGB10チップのはずだ。今回発表されたフラッグシップモデルのスペックが、これまでの情報とほぼ一致しているためだ。

FP4換算で最大1 PFLOPSのAI性能、20コアのCPU、6144コアのGPU、そして128GBのLPDDR5X統合メモリを搭載する。これにより、120Bモデルをローカル環境で軽々と実行できる。
今回の発表会では、ジェンスン・ハンがRTX Sparkを搭載するパートナーブランドのPCのコンセプトも披露した。

厚さ14mm、電源未接続のノートPC上で、90GBの3Dシーンをレンダリングし、12K解像度の動画を編集できるという。非常に驚異的な話だ。
しかも、薄型で爆発的な性能を持つ新しいノートPCだけでなく、Mac Miniのような低消費電力の小型ボックスも登場する。

最近のLenovoやHP、Armの株価高騰に意味があったのだ。消費者向けPCで統合メモリを採用し、超高速・フルCUDAエコシステム対応でローカルAI大規模モデルを動かせるのは、PC分野全体として初めてのことだ。
さらにMicrosoftはNVIDIAと共に、Windowsシステムを全面的に再構築し、RTX Spark搭載PCがローカルAgentをネイティブに実行できるようにする。Windowsエコシステムは救われる——NVIDIAが救世主となろうとしている。まさに「パーソナルPCの新時代」という表現は伊達ではない。来年、新しいWindowsシリーズへの換機需要が到来する予感がする。
統合メモリがローカルAIを変える
RTX Sparkの歴史的意義を理解するためには、「統合メモリ」とは何か、その用途は何かを知る必要がある。
従来のPCには、CPUとGPUという二つの中核コンポーネントが存在する。

GPUは皆がよく知っている通り、PC上では一般的にグラフィックスカード——例えば筆者のRTX 5080——として搭載される。

CPUとGPUは、それぞれ別々のメモリを持っていた。CPUが用いるのはシステムメモリ(RAM)であり、GPUが用いるのはビデオメモリ(VRAM)だ。両者は専用の通道を介してデータを行き来させる必要があった。
統合メモリは、これら二つを一つに統合し、CPUとGPUが同じメモリプールを共有して直接アクセスできるようにする仕組みだ。Appleはこの方式を主流として確立し、現在購入できるMacはほぼすべて統合メモリを採用している。

しかしWindowsエコシステムでは、CPUとGPUが異なるメーカー製であることが多く、過去のエコシステムの制約により、過去にも試みはあったが失敗に終わり、これほどの上下游を連携させて大規模に推進した例はなかった。これほどの大掛かりな動きを成功させたのは、NVIDIAが初めてだ。
この統合メモリは、大規模モデルを実行する上でまさに生死を分ける差だ。
前述した通り、従来のPCメモリアーキテクチャは分離型である。CPUはシステムメモリ(RAM)を、GPUはビデオメモリ(VRAM)を持ち、両者はPCIeと呼ばれるインターフェースで接続されている。

例えば、CPU側に64GBのRAMがあり、GPU側にRTX 5080の16GB VRAMがある状況を考えよう。ローカルで量子化済み70Bモデルを動かすには数十GBのメモリが必要だが、PCの総メモリは64GBに見えるものの、GPUが高速に使えるのはその16GB VRAMに限られる。モデルが大きくてVRAMに収まらなくなると、一部の重みをCPUのシステムメモリに置く必要が生じ、GPUはその重みが必要になるたびにPCIeを介してシステムメモリから読み出さなければならない。
GPUが自らのVRAMにアクセスする帯域は約1TB/sと非常に高速だ。しかしCPUメモリとGPUを接続するPCIeの通道——PCIe 4.0 x16の単方向帯域は約32GB/sに過ぎず、30倍もの差がある。事実上、亀のような速度だ。そのため、モデルは動作しないか、あるいは極めて遅い状態で実行されることになる。
統合メモリが主に解決するのは、この問題である。CPUとGPUのメモリを共有プールに統合し——例えば1台のマシンに128GBの統合メモリがあれば——GPUはこの大きなプールの大部分を直接利用できる。これにより、ローカル大規模モデルを実行する際、1枚のグラフィックスカードの16GB、24GB、32GBといったVRAMの制限にこれほど縛られなくなる。統合メモリは、コンシューマー向け単体マシンにおいて、ローカル大規模モデルを実行する唯一かつ最もエレガントな解決策である。データセンターの世界はまた別の話であり、一般消費者には関係がない。
CUDAというエコシステムの壁
ここで当然の疑問が生じる。統合メモリがこれほど優秀なら、Macを買えばいいのではないか。128GB統合メモリモデルのMacも存在する。なぜRTX Sparkが必要なのか。
これは極めて重要な問いであり、その答えこそがNVIDIAの真のキラー機能である。CUDAだ。
CUDAという言葉は、AIに関心のある読者なら聞いたことがあるだろう。しかし、それが具体的に何であり、なぜこれほど重要なのかは、真剣に語る価値がある。
多くの人はCUDAをNVIDIAのグラフィックスドライバか、あるいは単なるGPU加速技術だと考えている。その理解も完全に誤りではないが、CUDAの実体ははるかに巨大だ。
CUDAは、究極のエコシステムだ。

その底層では、GPUを汎用計算器としてプログラミングでき、描画以外の数学演算も可能にする。
中間層には、20年近く磨き上げられた数学ライブラリ群が存在する。線形代数のcuBLAS、ディープラーニング基礎演算のcuDNN、推論最適化のTensorRT、マルチGPU通信のNCCL、そしてFlashAttentionのような重要な最適化も、CUDAルート上で最も成熟しており、多くの新機能はNVIDIA GPUを中心に優先的に適配される。
そして今回の講演でジェンスン・ハンが繰り返し強調したCUDA-X——すべてのAgentに開放されたCUDAライブラリ群——により、Agentが直接ライブラリを呼び出せるようになり、さらに驚異的な世界が開ける。

これには科学計算、エンジニアリングシミュレーション、チップ設計、ゲノミクス、通信ネットワーク、ロボティクス、物理シミュレーションなど、あらゆる分野の加速ライブラリ群が含まれる。
例えば計算露光のcuLitho、意思決定最適化のcuOpt、疎行列求解のcuDSS、構造化・非構造化ドキュメントの深層分析のAI-Q、微分可能物理のWarp、ゲノミクスのParabricksなどなど。

ジェンスン・ハンの言葉を借りれば——数学は、あまりに素晴らしい。CUDAは、あまりに強力だ。
その上層には、PyTorch、TensorFlow、JAX——ほぼすべてのディープラーニングフレームワークのGPUバックエンドで、デフォルトかつ最優先でサポートされるのがCUDAだ。
2006年から現在まで、CUDAは膨大な量の最適化ライブラリ、チュートリアル、コード、エコシステムを蓄積してきた。現在公開されている学術論文のオープンソースコードの圧倒的多数はCUDA上で書かれ、テストされている。ディープラーニングに関するあらゆる問題の解決策を検索すれば、答えのほぼすべてはCUDAを使用している前提で語られている。
AIエンジニアリング界の母語は、CUDAなのだ。
これは、Appleが常に抱えてきた痛点でもある。Appleの統合メモリは確かに優秀だが、そのGPUはMetalを使用し、機械学習フレームワークはMLXである。コミュニティの圧倒的多数のオープンソースモデル、学習コード、ファインチューニングツールは、まずCUDA上で完成され、その後ようやくMLXへの移植が行われる。推論はまだしも、学習とファインチューニングにおけるApple上のエコシステムは、今日もなお非常に脆弱だ。
こうして理解できたはずだ。なぜRTX Sparkが業界全体の期待を集めているのか。
RTX Spark以前、PC上でCUDAを求め、統合メモリの効率性も求める——この二つは両立不可能だった。
RTX Sparkは、これまで相容れなかった二者を初めて一つに融合させた。これまでいかなる単一プラットフォームも提供できなかった組み合わせだ。
これこそが、RTX Sparkの真に最も強力な点であり、最大の差別化要因である。人類が今まで創造してきたすべてのコンピューティングに加え、Agentも動かす——そのために必要なのは、CUDAエコシステムに基づく環境だ。
Windowsエージェント時代の基盤づくり
このCUDAエコシステムを土台に、今回AdobeなどもRTX Spark向けに全面的な最適化を行う。
例えばAdobeは、RTX Spark向けにPhotoshopとPremiereのコアアーキテクチャを完全に再設計し、最大2倍の速度を実現したうえで、Agentのネイティブ呼び出しにも対応する。

そして今回、NVIDIAとMicrosoftは手を携えて、Windows上のAgentエコシステムを再構築する。詳細は後日サティア・ナデラとのライブ対談で語られるが、すでに一部が明かされている。
新しいWindowsセキュリティプリミティブにより、Agentのネイティブ構築と実行に対して、ID認証、隔離保護、ポリシー管理、エンドツーエンドのセキュリティ能力を提供する。そしてNVIDIA独自のOpenShellも登場する。
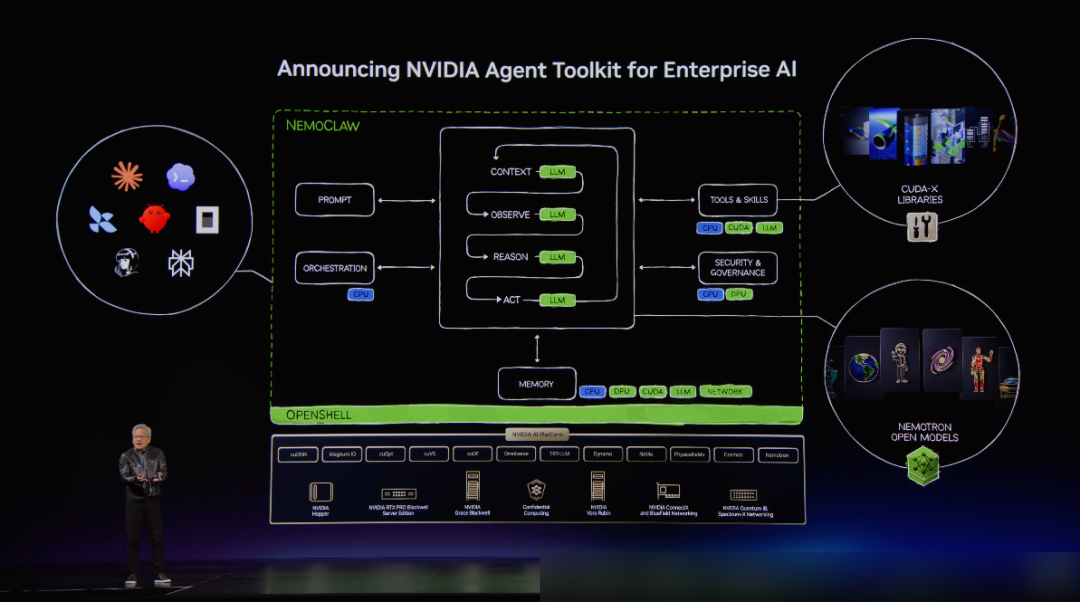
これにより、Agent向けのWindows PCプラットフォーム全体像が見えてくる。底層はRTX Sparkが提供するハードウェア能力。第二層はMicrosoftがAgent時代へと進化させるWindowsシステム。第三層はセキュアな実行環境——すなわちWindows security primitives + NVIDIA OpenShellである。
これにより、ローカルPCで大規模モデルを実行したい開発者やクリエイターにとって、ハードウェア面でRTX Spark搭載マシンはほぼ最適解となる。もしゲームもプレイしたいなら、選択肢は他にない。RTX Sparkのみだ。
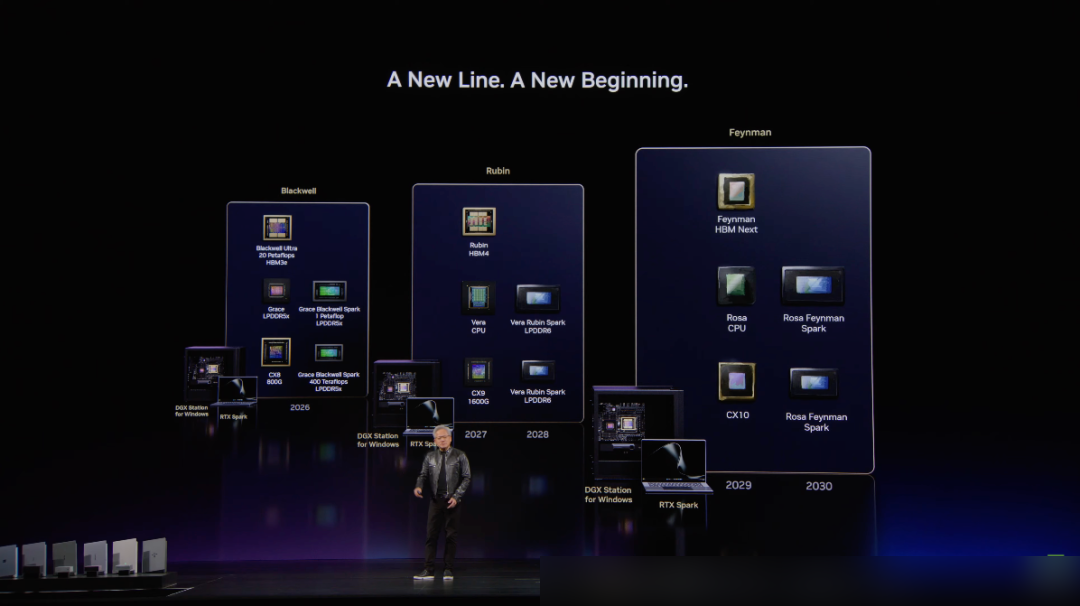
A New Line, A New Beginning.
これが、パーソナルPCの新時代だ。
それは、人間のためだけでなく、Agentのためにも設計されている。過去と互換性を持ちながら、過去を携えて、次の未来へと歩み出す。
関連記事
読み込み中...