DeepSeek V4が発表:100万トークンのコンテキストと华为チップへの最適化でNVIDIA独占を打破へ
DeepSeekがV4シリーズモデルのプレビュー版を正式に発表し、オープンソース化した。今回のアップデートでは、両モデルともに100万トークンのコンテキストウィンドウを標準搭載しているのが大きな特徴だ。

- DeepSeek-V4-Pro: パラメータ数 1.6T(アクティブパラメータ 49B)
- DeepSeek-V4-Flash: パラメータ数 284B(アクティブパラメータ 13B)
これらは公式サイト(chat.deepseek.com)や公式アプリで体験可能で、APIサービスも同時に提供が開始された。
Agent能力の劇的な向上
今回のアップグレードにおいて最も核心となる方向性はAgent機能の強化だ。V4-Proは既にDeepSeek内部でAgentic Codingツールとして日常的に使用されており、社員のフィードバックでは「Sonnet 4.5よりも使い勝手が良く、成果物の品質はOpus 4.6の非思考モードに近い」と評価されている。
内部のR&Dプログラミングベンチマーク(50人以上のエンジニアによる約200件の実際のタスク)では、V4-Pro-Maxのパス率(Pass Rate)は67%であり、Sonnet 4.5の47%を大きく上回った。一方、Opus 4.6 Thinkingの80%にはまだ差がある。
内部調査に参加した85名の開発者および研究者のうち、9割以上がV4-Proを「最優先またはそれに近いプログラミングモデル」として選択できると考えている。また、Claude Code、OpenClaw、OpenCode、CodeBuddyなどの主要なAgent製品への最適化も行われ、コードタスクとドキュメント生成の両面で向上が見られた。
ツール利用(Tool Call)に関しては、新しいXML形式のスキーマを導入し、「|DSML|」という特殊トークンで境界を定義することで、エスケープ失敗や呼び出しエラーを大幅に削減し、前世代よりも高い信頼性を実現している。
知識量と推論能力のベンチマーク
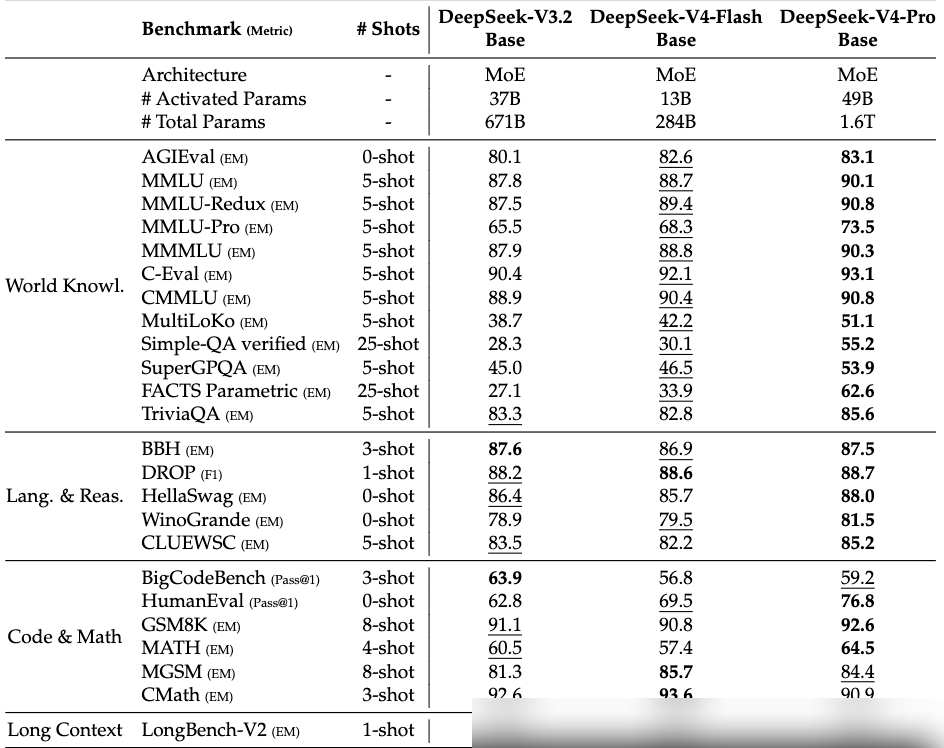
知識と推論の面では、V4-Proは世界知識の評価で他のオープンソースモデルを圧倒している。SimpleQA-Verifiedのスコアは57.9で、僅差のオープンソース競合を約20ポイント上回り、Gemini-3.1-Pro(75.6)に迫る結果となった。数学、STEM、競技プログラミングの3項目では、公開されている全てのオープンソースモデルを凌駕し、トップレベルのクローズドモデルに匹敵する水準に達している。
基座モデル(Base Model)であるV4-Pro-Baseは、MMLU 5-shotで90.1、MMLU-Pro 5-shotで73.5を記録し、パラメータ数が近いV3.2-Baseを全面的に上回った。特筆すべきは、より小型のV4-Flash-Baseであっても、多くのベンチマークでV3.2-Baseを超えており、アーキテクチャの改善による効率向上が顕著である点だ。
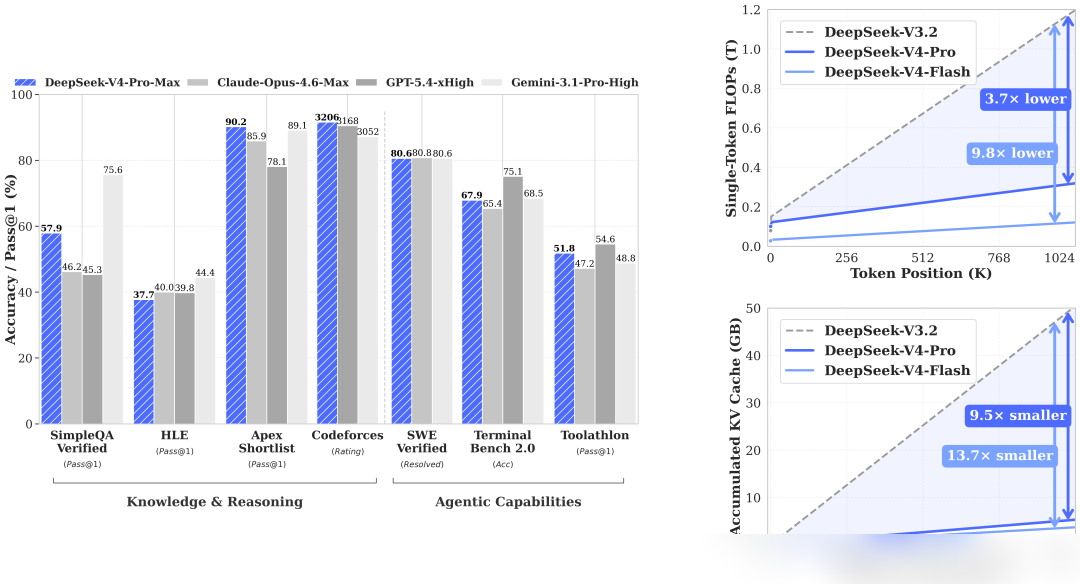
Codeforcesの人間ランキングでは、V4-Pro-Maxが現在23位に位置している。また、IMOAnswerBench Pass@1は89.8に達し、GPT-5.4の91.4に次ぐ性能となった。Agent評価のSWE Verified Resolvedは80.6で、Opus-4.6 Max(80.8)とほぼ同等である。
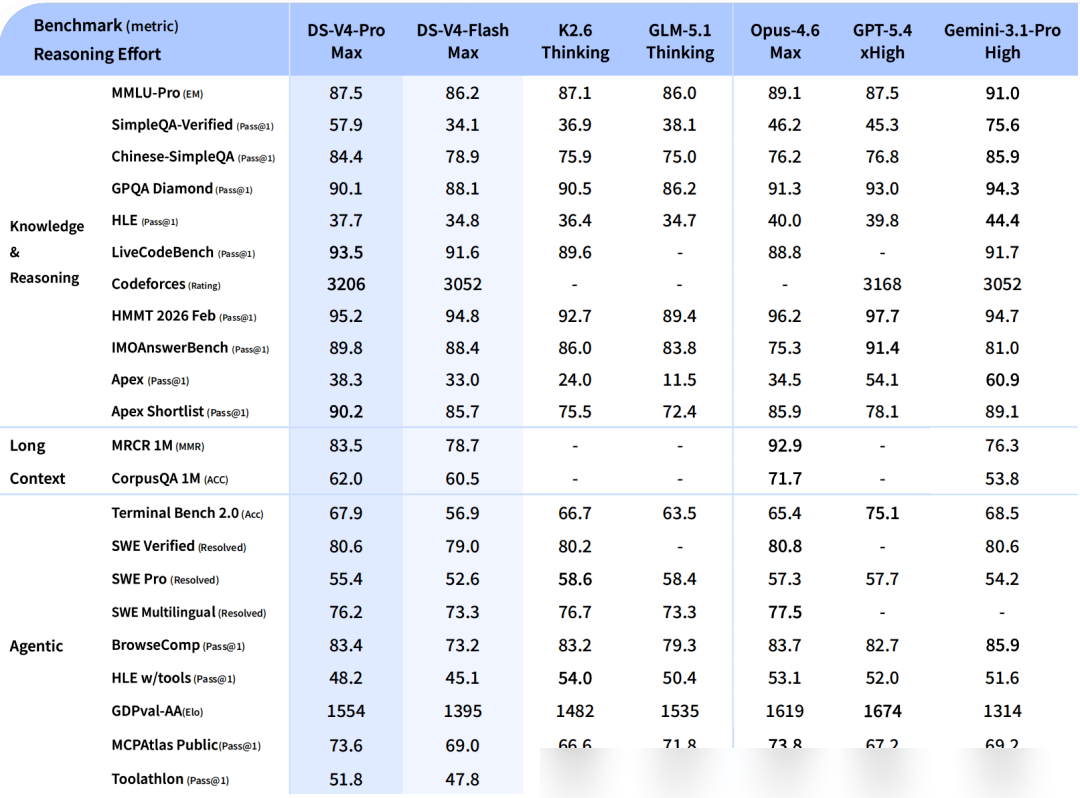
長文コンテキストの評価では、1MトークンのシナリオでGemini-3.1-Proを上回る結果が出た。128Kまでは非常に安定しており、それを超えると低下し始めるものの、1M時点での性能は依然として多くの同類モデルを上回っている。
「Flash」を過小評価してはいけない:思考モードの選択こそが重要
V4-Flashは単なる「低スペック版」ではない。API価格に競争力がありつつ、推論能力はProに近い。特に「Think Max」モードを使用した場合、V4-Flashの推論性能はProに大幅に近づく。LiveCodeBench Flash Maxで91.6を記録するなど、Pro Maxとの差は極めて限定的だ。

重要なのはバージョン選びよりも「思考強度(reasoning_effort)」の選択である。V4-Proを例に挙げると、HLE Pass@1は非思考モードの7.7からMaxモードでは37.7へと飛躍的に向上する。複雑なタスクにおいては、適切な思考強度を選択することが性能を最大限に引き出す鍵となる。
両モデルは以下の3つの推論強度をサポートしている:
- 非思考モード: 応答速度が速く、日常的な軽量タスク向け。
- Think High: 明示的な論理推論を有効化し、複雑な問題やプランニングに適している。
- Think Max: 推論能力を最大限に活用。コンテキストウィンドウを384K以上に設定することが推奨される。
Think Maxモードでは、システムプロンプトの冒頭に「最大限の強度で推論し、近道をせず、全ての推論ステップと否定された仮説を明示的に書き出すこと」という指示が注入される。これにより、同一モデルであってもモードによって劇的な性能差が生まれる。
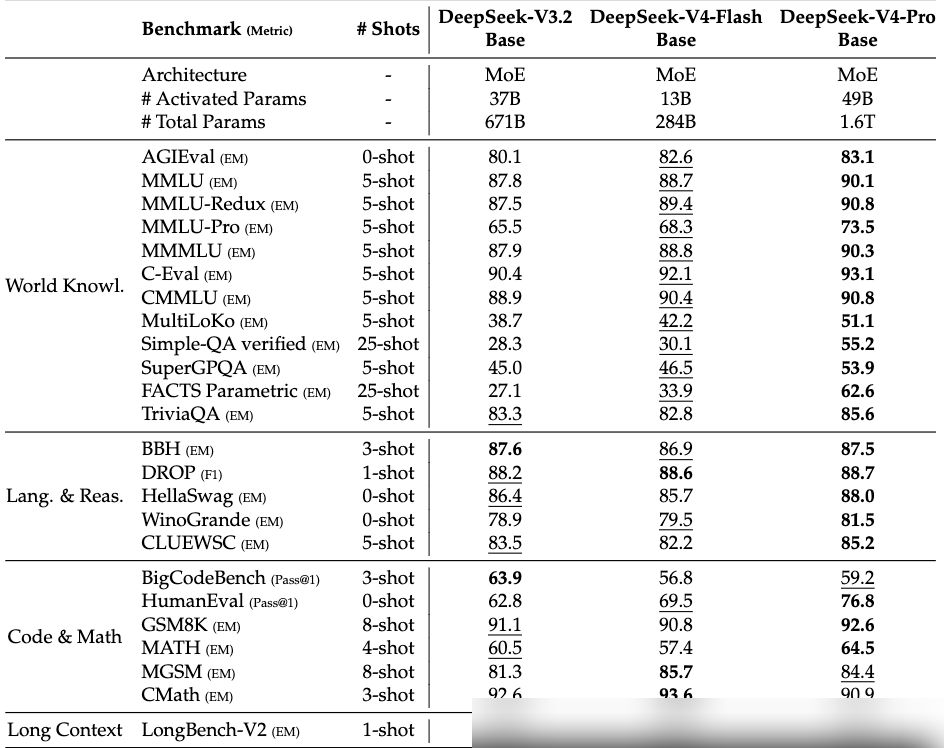
100万トークンを支えるアーキテクチャの革新
DeepSeek V4は、1Mトークンのコンテキストを効率的に処理するため、アテンションメカニズムに大幅な変更を加えた。
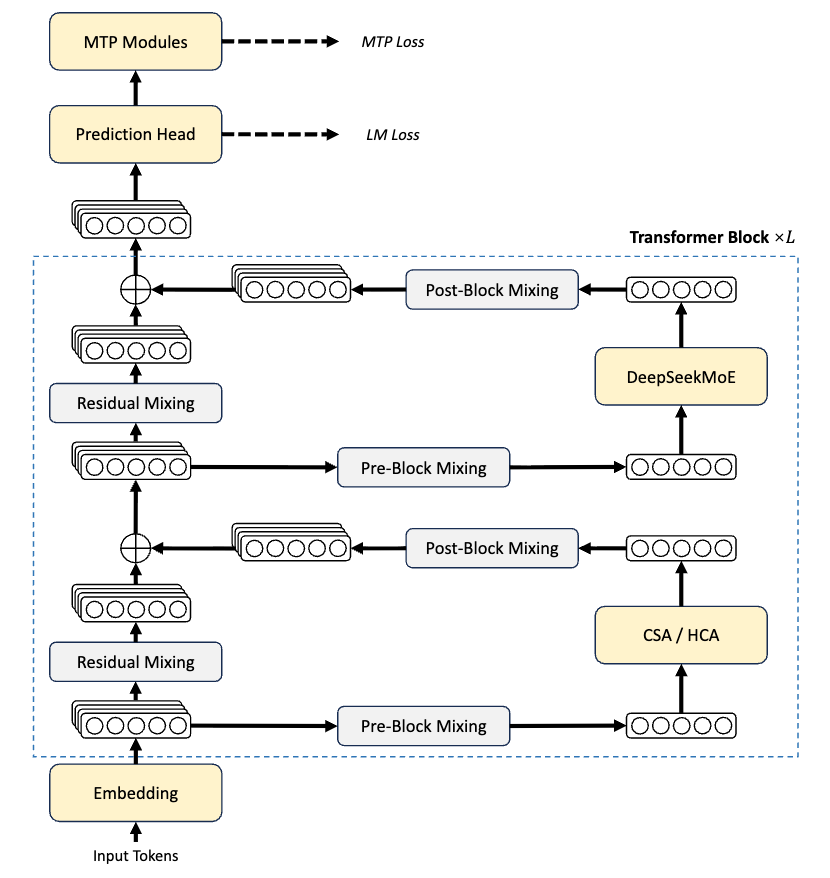
従来のアテンション計算量はシーケンス長の2乗で増加するため、長文コンテキストでは計算上のボトルネックとなる。V4では2種類の圧縮アテンションを交互に使用する仕組みを導入した。
- CSA (Compressed Sparse Attention): $m$個のトークンのKVキャッシュを1つに圧縮し、スパースアテンションを用いてその中から$k$個のみを選別して計算に利用する。
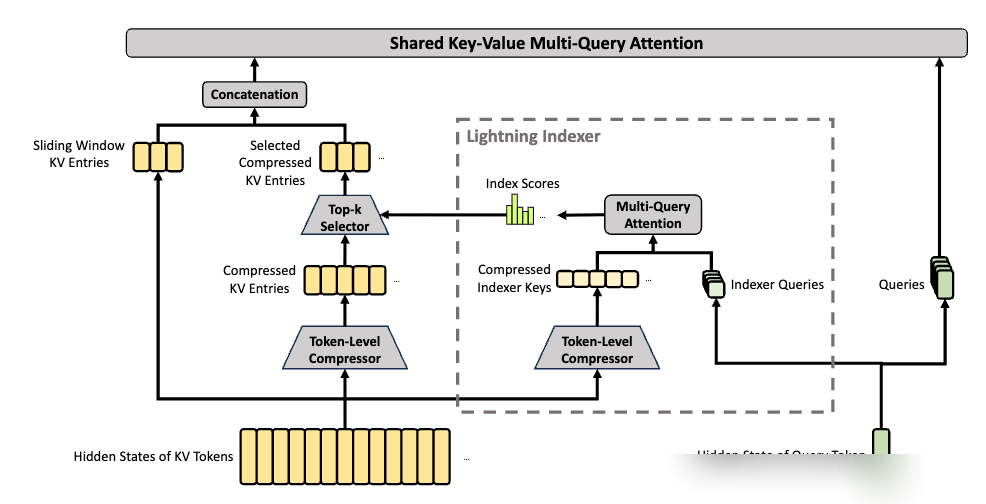
- HCA (Hierarchical Compressed Attention): より高い圧縮率でより長い区間を1つに圧縮し、稠密(Dense)アテンションを維持する。
さらにCSAには「Lightning Indexer」が搭載されており、FP4低精度でクエリトークンと圧縮ブロック間の相関スコアを高速に算出し、計算量をさらに削減している。局所的な詳細を失わないよう、両アテンションにスライディングウィンドウ分岐を導入している点も特徴だ。
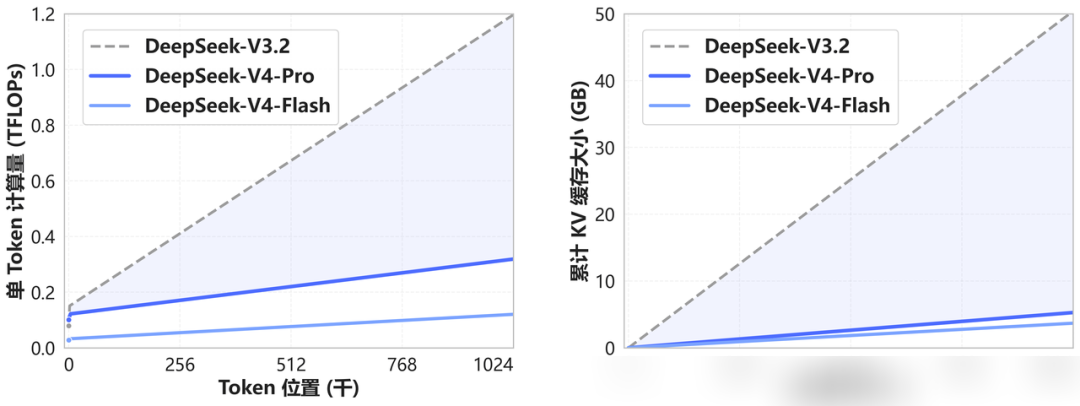
この結果、1MコンテキストにおけるV4-Proの単一トークン推論計算量はV3.2の27%に抑えられ、KVキャッシュの占有量は10%まで削減された。V4-Flashはさらに積極的で、計算量はV3.2の10%、KVキャッシュは7%まで削減されている。
学習の最適化と安定化
残差接続を強化するために「manifold Constrained Hyper-connection (mHC)」を導入。信号伝達を安定させ、層を跨ぐ情報の伝播を最適化した。最適化手法としては、Muon最適化器を導入し、勾配行列を反復的に直交化することで収敛速度と安定性を向上させている。多くをMuonで処理し、Embedding層や予測ヘッドなどはAdamWを併用するハイブリッド構成だ。
また、学習中の「Loss Spike(損失急増)」問題に対し、以下の2つの対策を講じている:
- 予測的ルーティング (Anticipatory Routing): 更新をデクープし、悪循環を打破する。
- SwiGLUの線形成分のクリッピング: 数値範囲を $[-10, 10]$ に制限し、異常値の発生を抑制する。

モデルは32Tトークン以上の高品質データで事前学習され、SFTとGRPO(グループ相対方策最適化)による強化学習を経て、オンライン蒸留(OPD)によって各領域の能力を単一モデルに統合している。
オープンソース展開とデプロイ
4つの重みバージョンがオープンソースで公開されており、HuggingFaceやModelScopeからダウンロード可能だ。精度はFP8 Mixed(Base版)およびFP4/FP8混合精度(指令調整版)が採用されている。FP4からFP8への逆量化は、ダイナミックレンジの差によりロスなく行われる。
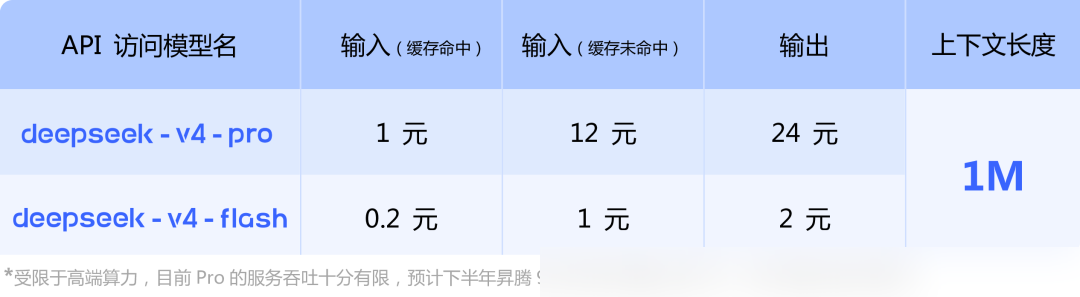
API利用においては、OpenAI ChatCompletionsおよびAnthropicの両インターフェースをサポート。モデルパラメータを deepseek-v4-pro または deepseek-v4-flash に変更するだけで利用可能だ。
NVIDIA独占を打破する「国産チップ」戦略
技術的な側面以上に注目すべきは、DeepSeek V4がNVIDIAではなく、中国国産チップ(昇騰/Ascend)で首積み的に最適化された点だ。
DeepSeekはNVIDIAやAMDに先駆けて先行アクセス権を国産チップメーカーに提供した。これにより、「アルゴリズムは自社開発、コードはオープンソース、チップは国産」というエコシステムが完結することになる。
NVIDIAのジェンスン・ファンCEOは最近のインタビューで、DeepSeekの進展を軽視せず、むしろ「AIモデルが中国のハードウェアで最適に動作するように構築され、それが世界に拡散することで中国の技術が世界標準になること」への危惧を示している。
1兆パラメータ級のモデルを昇騰チップで動作させた実績は、中国国内の計算リソースエコシステムにとって強力な後押しとなり、他のチップメーカー(Cambricon、Hygon等)の適応加速を促すと予想される。
関連記事
- DeepSeekの公式サイトに新モデルが登場か?最大100万トークンの入力と2025年5月の知識カットオフを確認
- [Cursor Composer 2.5公開:Kimi 2.5ベースで性能を維持しつつコストを1/10に削減](/blog/cursor-composer-25-kimi-25-1-10)
- 中国LLMで吹き荒れる資金調達ラッシュ:次に淘汰されるのは誰か?
読み込み中...