Claude Opus 4.8 Released: SWE-Bench Pro 69.2%, 10.6-Point Lead Over GPT-5.5 — Anthropic's New Standard for Agent Quality

On May 28, 2026, Anthropic officially released Claude Opus 4.8, the latest iteration of its flagship model. Arriving just six weeks after Opus 4.7 at an unchanged price point, it outperforms both OpenAI's GPT-5.5 and Google's Gemini 3.1 Pro across agentic coding, reasoning, and computer-use benchmarks.
The Numbers That Matter
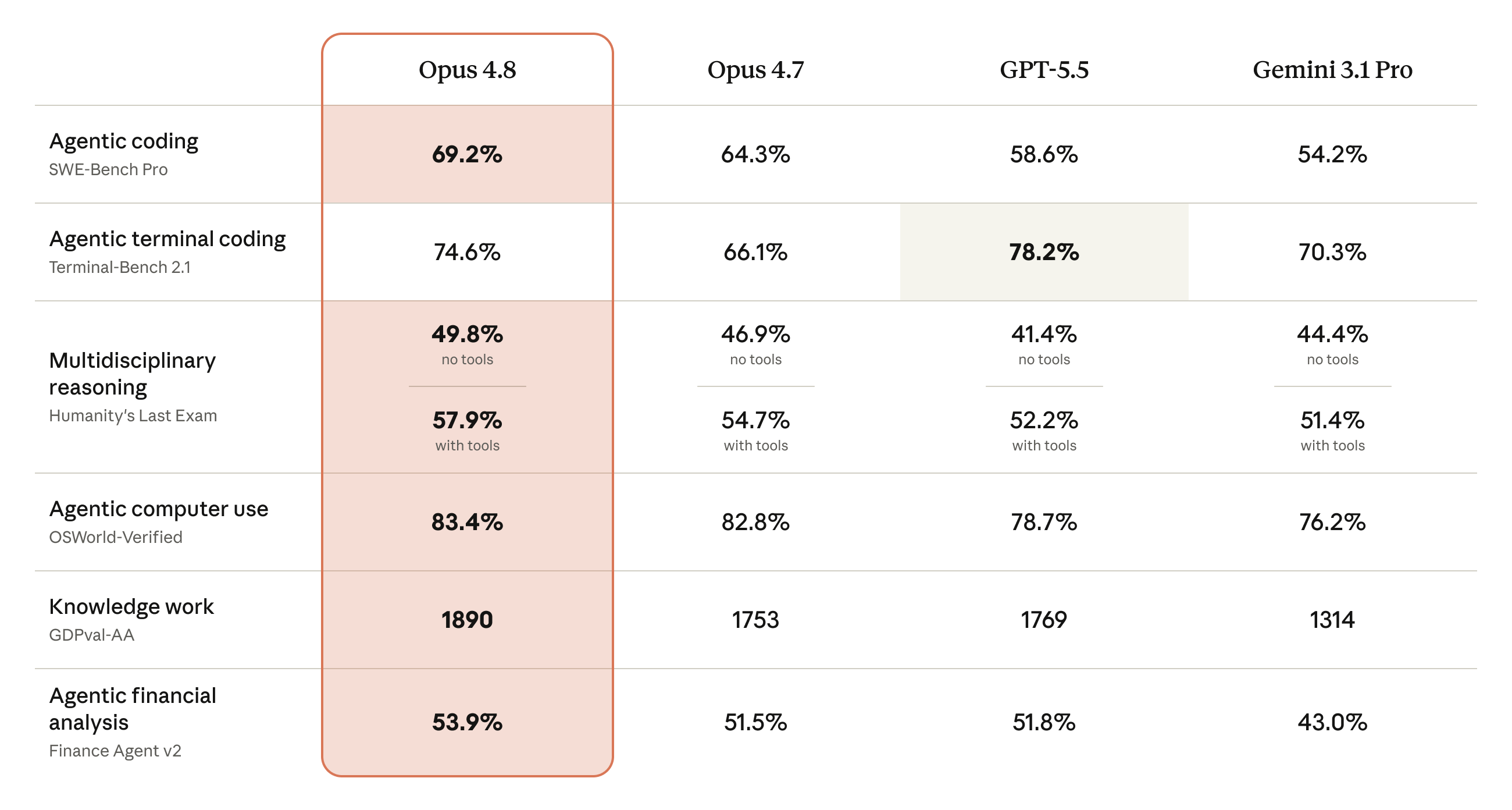
Agentic Coding: SWE-Bench Pro
| Model | Score |
|---|---|
| Claude Opus 4.8 | 69.2% |
| Claude Opus 4.7 | 64.3% |
| GPT-5.5 | 58.6% |
| Gemini 3.1 Pro | 54.2% |
A 4.9-point improvement over the previous model and a 10.6-point lead over GPT-5.5. SWE-Bench Pro measures real software engineering tasks — not code generation in isolation, but the ability to autonomously solve engineering problems as an agent.
Multidisciplinary Reasoning: Humanity's Last Exam
| Model | Without Tools | With Tools |
|---|---|---|
| Claude Opus 4.8 | 49.8% | 57.9% |
| GPT-5.5 | — | 52.2% |
| Gemini 3.1 Pro | — | 51.4% |
A 5.7-point advantage over GPT-5.5 with tools enabled on this cross-disciplinary benchmark spanning mathematics, science, and humanities.
Computer Use: OSWorld-Verified
| Model | Score |
|---|---|
| Claude Opus 4.8 | 83.4% |
| Claude Opus 4.7 | 82.3% |
| GPT-5.5 | 78.7% |
| Gemini 3.1 Pro | 76.2% |
The browser agent component scored 84% on Online-Mind2Web, surpassing both Opus 4.7 and GPT-5.5.
Knowledge Work: GDPval-AA
| Model | Score |
|---|---|
| Claude Opus 4.8 | 1890 |
| GPT-5.5 | 1769 |
| Claude Opus 4.7 | 1753 |
The One Reversal: Terminal-Bench 2.1
| Model | Score |
|---|---|
| GPT-5.5 | 78.2% |
| Claude Opus 4.8 | 74.6% |
| Gemini 3.1 Pro | 70.3% |
| Claude Opus 4.7 | 66.1% |
GPT-5.5 leads by 3.6 points in terminal coding. However, Opus 4.8 improved 8.5 points over 4.7, and the gap is narrowing.
4x More Accurate: The Code Quality Revolution
Beyond benchmark numbers, the qualitative shift in code quality is striking. Anthropic reports that Opus 4.8 is "approximately four times less likely than Opus 4.7 to let flaws in generated code pass without comment."
This represents a leap in self-verification capability:
- Significantly increased frequency of flagging bugs in its own code
- Stronger tendency to challenge problematic plans
- Improved ability to recognize and communicate uncertainty
- Reduced frequency of making unsupported claims
Cursor CEO Michael Truell noted: "Opus 4.8 exceeds prior Opus models across every effort level on CursorBench. Tool calling is meaningfully more efficient, using fewer steps for the same intelligence."
Cognition CEO Scott Wu added: "It fixes the comment-verbosity and tool-calling issues from Opus 4.7. Tool use is cleaner."
Pricing and Fast Mode
| Model | Input | Output |
|---|---|---|
| Claude Opus 4.8 (Standard) | $5/MTok | $25/MTok |
| Claude Opus 4.8 (Fast Mode) | $10/MTok | $50/MTok |
| Claude Opus 4.7 | $5/MTok | $25/MTok |
Standard pricing is identical to Opus 4.7. Fast Mode delivers 2.5x the speed at one-third the cost of previous Fast Mode pricing. Switching is instant via the /fast command in Claude Code.
Databricks CTO Hanlin Tang reported real-world cost reductions of 61% compared to Opus 4.7 — not just from Fast Mode pricing, but from improved agent efficiency reducing total token consumption.
Dynamic Workflows: Hundreds of Parallel Subagents
Launching alongside Opus 4.8, Dynamic Workflows is a new Claude Code feature available as a research preview for Enterprise, Team, and Max plans.
The feature enables Claude to plan work and execute hundreds of parallel subagents within a single session. Key capabilities:
- Codebase-scale migrations: End-to-end changes across hundreds of thousands of lines of code, from planning to merge
- Automatic output verification: Each subagent's output is verified before reporting
- Test suite as quality bar: Existing test suites serve as the quality standard
Shopify Staff Engineer Tom Pritchard observed: "It has noticeably better judgment. It builds up confidence around complex, multi-service explorations."
Messages API Update
A significant change for developers: system entries can now be placed inside the messages array. This allows updating Claude's instructions mid-task without breaking the prompt cache or routing through a user turn — enabling dynamic permission changes, token budget adjustments, and environment context updates during long-running agent tasks.
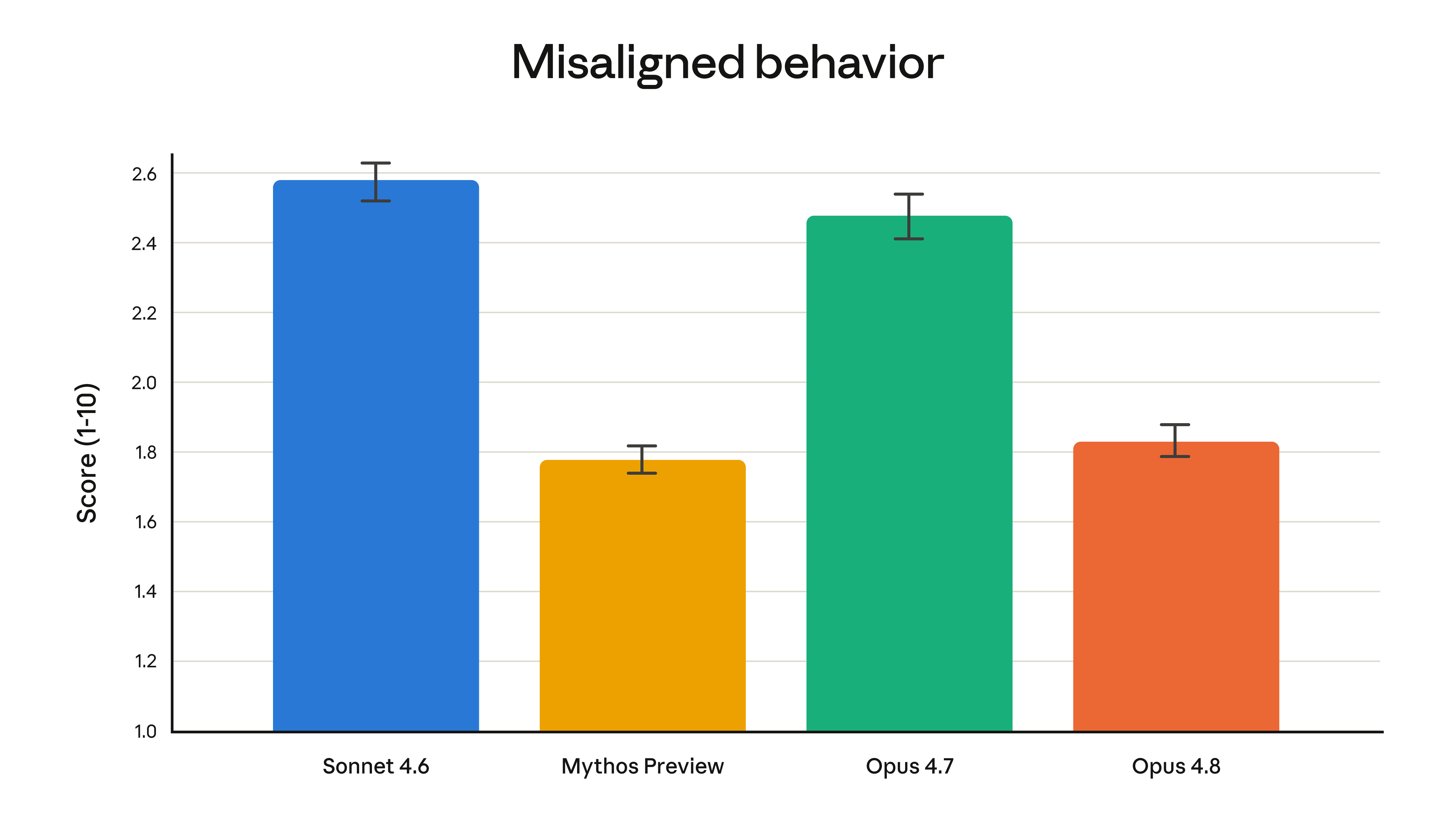
Alignment Improvements
| Model | Misalignment Score |
|---|---|
| Claude Opus 4.8 | ~1.83 |
| Claude Opus 4.7 | 2.47 |
Lower is better. Opus 4.8's score of 1.83 matches Mythos Preview, Anthropic's most aligned model. This composite score measures supportive behavior, respect for user autonomy, and prosocial traits — critical for agents operating without constant human oversight.
Ecosystem Validation
| Company | Assessment |
|---|---|
| Databricks | Step change in agentic reasoning. 61% token cost reduction on Genie agent |
| Thomson Reuters | Improved consistency and reasoning in CoCounsel Legal workflows |
| Hebbia | Better citation precision and token efficiency on dense financial filings |
| Cursor | Exceeds all prior Opus models at every effort level on CursorBench |
| Shopify | Better judgment in complex multi-service explorations |
Effort Control and What's Next
Claude.ai and Cowork now feature an "Effort Control" slider alongside the model selector. Higher effort means deeper reasoning and better responses; lower effort means faster responses with less rate limit consumption. Available on all plans.
Anthropic also disclosed details about its next-generation model, Claude Mythos (Project Glasswing). This model class exceeds Opus-level intelligence and is currently in limited testing with Amazon, Microsoft, and Apple for cybersecurity applications. General availability is expected "in the coming weeks" after meeting stronger safety benchmarks.
Conclusion
Claude Opus 4.8 is Anthropic's answer to the question: "Can we trust this agent?" SWE-Bench Pro 69.2%, OSWorld-Verified 83.4%, Humanity's Last Exam 57.9% — all surpassing GPT-5.5 with substantial improvement margins.
Yet GPT-5.5's lead on Terminal-Bench 2.1 shows that dominance in specific domains remains contested. In this rapidly evolving competitive landscape, Opus 4.8 is the strongest contender as of May 2026, but that position is not permanent.
The true differentiator lies in the ability to orchestrate hundreds of subagents (Dynamic Workflows) and the alignment score of 1.83 (safe, reliable autonomous behavior). From a model that executes individual tasks accurately to an agent that autonomously drives complex projects — Opus 4.8 marks a clear inflection point.

- Official Announcement: [Introducing Claude Opus 4.8 — Anthropic](https://www.anthropic.com/news/claude-opus-4-8)
- Product Page: [Claude Opus 4.8 — Anthropic](https://www.anthropic.com/claude/opus)
- API Documentation: Pricing — Claude API Docs
Loading...