DeepSeek V4 Unveiled: 1M Context Window and a Strategic Shift Toward Non-NVIDIA Hardware
DeepSeek has officially released the preview versions of its V4 series models under an open-source license. The standout feature of this update is the integration of a standard 1-million-token context window across the entire lineup.

- DeepSeek-V4-Pro: 1.6T total parameters (49B active)
- DeepSeek-V4-Flash: 284B total parameters (13B active)
These models are available via the official website (chat.deepseek.com), the official app, and a newly launched API service.
Massive Leap in Agentic Capabilities
The core objective of the V4 upgrade is the enhancement of AI Agent functionality. V4-Pro is already deployed internally as an agentic coding tool; internal feedback suggests it is more intuitive than Sonnet 4.5, with output quality closely mirroring Opus 4.6 in non-thinking mode.
In internal R&D programming benchmarks involving over 200 real-world tasks completed by 50+ engineers, V4-Pro-Max achieved a pass rate of 67%, significantly outperforming Sonnet 4.5's 47%, though it still trails Opus 4.6 Thinking (80%).
Over 90% of the 85 participating developers and researchers identified V4-Pro as their primary or secondary preferred coding model. The model has also been optimized for major agent frameworks such as Claude Code, OpenClaw, OpenCode, and CodeBuddy, showing marked improvements in both code generation and documentation tasks.
Regarding tool use (Tool calling), DeepSeek introduced a new XML schema using the special token |DSML| to define boundaries. This drastically reduces escape failures and call errors, providing much higher reliability than previous generations.
Knowledge and Reasoning Benchmarks
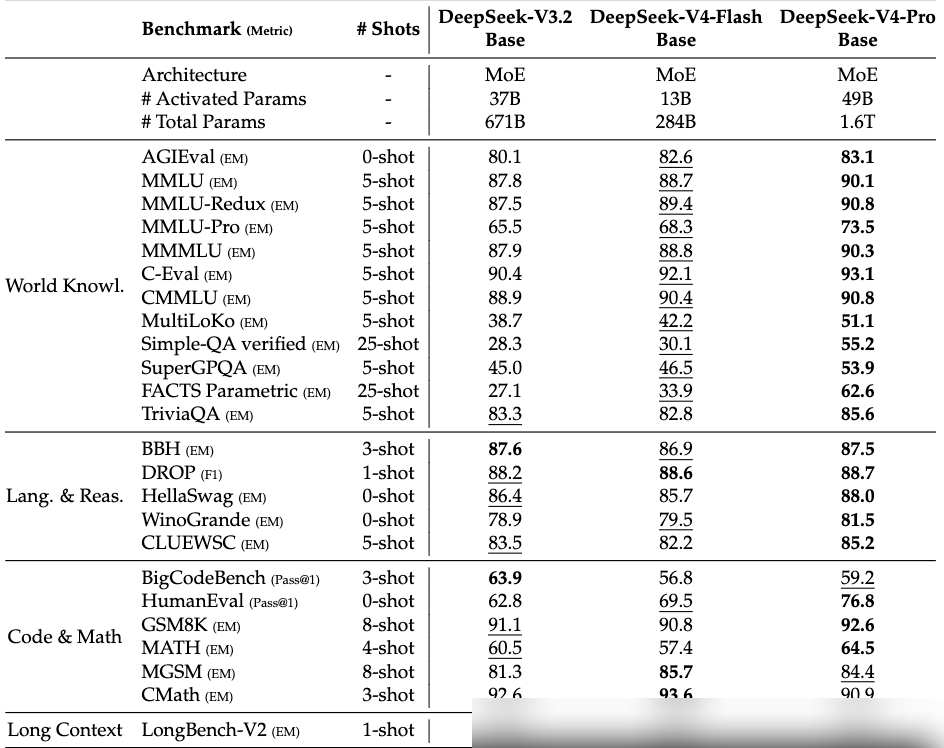
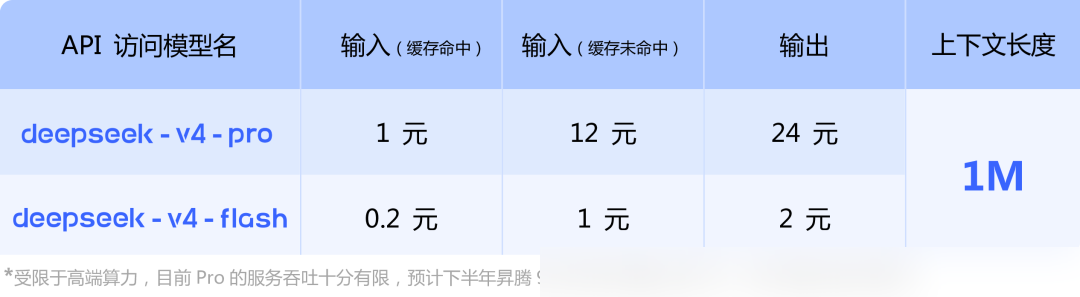
In terms of general knowledge, V4-Pro dominates other open-source models. It scored 57.9 on SimpleQA-Verified, beating close open-source competitors by roughly 20 points and narrowing the gap with Gemini-3.1-Pro (75.6). In Mathematics, STEM, and Competitive Programming, it surpasses all available open-source models, reaching parity with top-tier closed models.
The base model, V4-Pro-Base, recorded 90.1 on MMLU 5-shot and 73.5 on MMLU-Pro 5-shot, fully eclipsing the V3.2-Base. Notably, even the smaller V4-Flash-Base outperformed V3.2-Base in several benchmarks, highlighting the efficiency gains from architectural improvements.
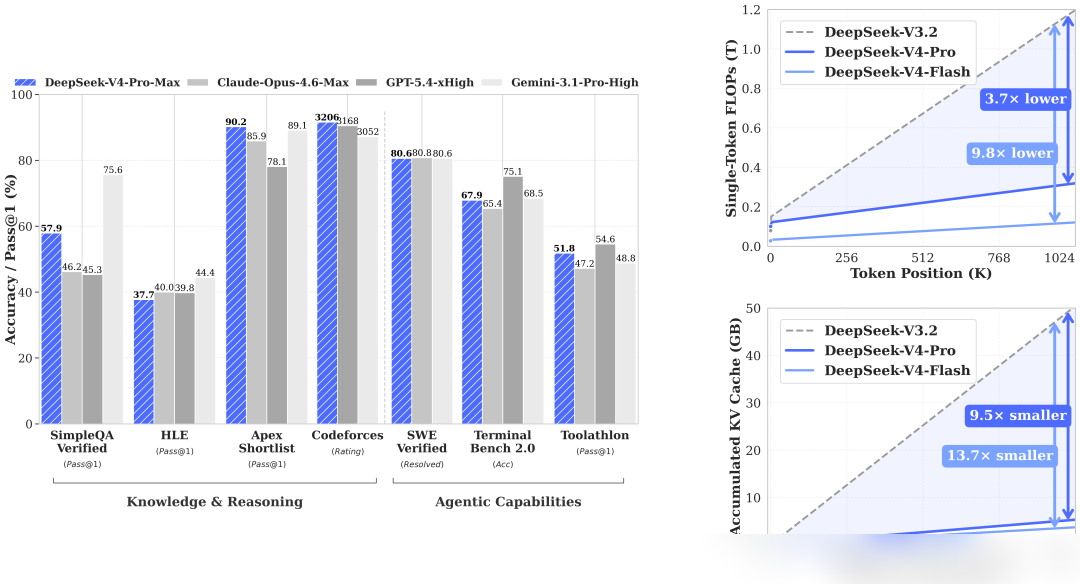
On the Codeforces human ranking, V4-Pro-Max currently sits at 23rd. Furthermore, its IMOAnswerBench Pass@1 reached 89.8, second only to GPT-5.4 (91.4). For agent evaluation, the SWE Verified Resolved score is 80.6, nearly identical to Opus-4.6 Max (80.8).
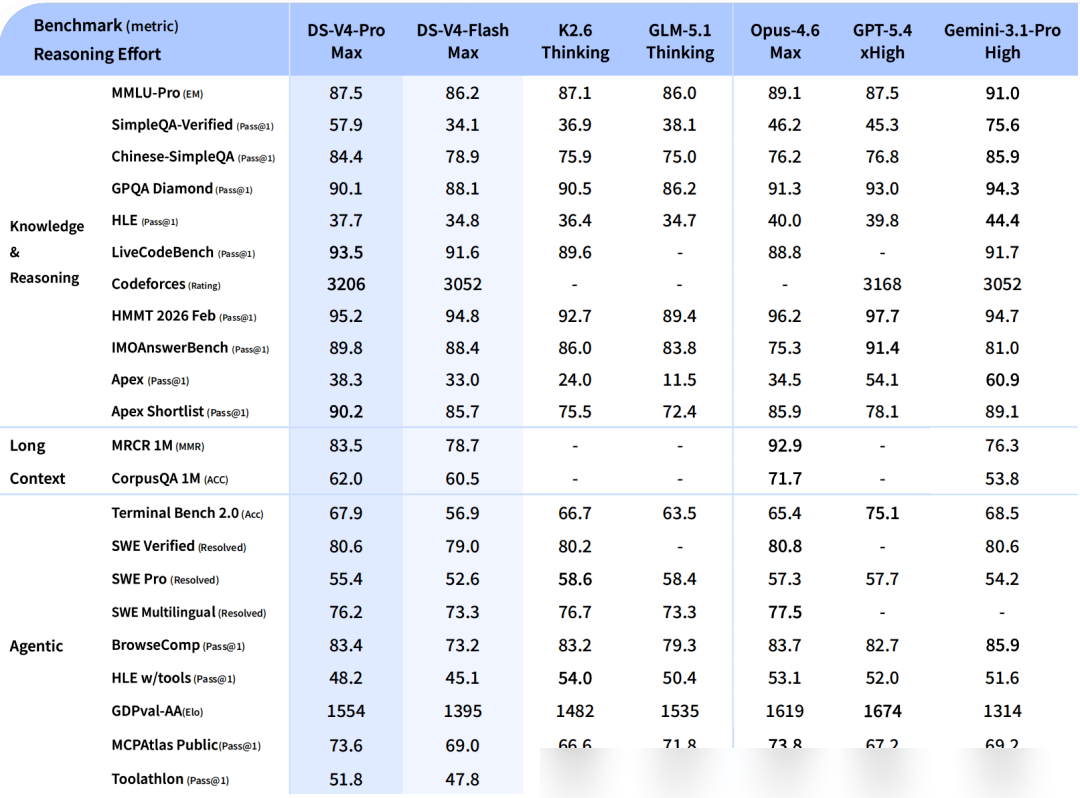
Evaluation of long-context performance shows that V4 exceeds Gemini-3.1-Pro in 1M token scenarios. While stability is rock-solid up to 128K and begins to dip thereafter, performance at the 1M mark remains superior to most comparable models.
Don't Underestimate "Flash": The Importance of Reasoning Effort
V4-Flash is not merely a "lite" version. While it offers highly competitive API pricing, its reasoning capabilities approach those of the Pro model. Specifically, when using "Think Max" mode, the performance gap narrows significantly, as seen in the LiveCodeBench Flash Max score of 91.6.

The key is not just the model version, but the selection of reasoning_effort. For instance, V4-Pro's HLE Pass@1 jumps from 7.7 in non-thinking mode to 37.7 in Max mode. For complex tasks, selecting the appropriate reasoning intensity is critical to unlocking peak performance.
Both models support three reasoning intensities:
- Non-Thinking Mode: Fast response times, ideal for lightweight daily tasks.
- Think High: Enables explicit logical reasoning; suitable for complex problem solving and planning.
- Think Max: Maximizes reasoning power. Setting a context window of 384K or higher is recommended.
In Think Max mode, the system prompt is injected with instructions to "reason with maximum intensity, avoid shortcuts, and explicitly document all reasoning steps and refuted hypotheses," leading to dramatic performance gains.
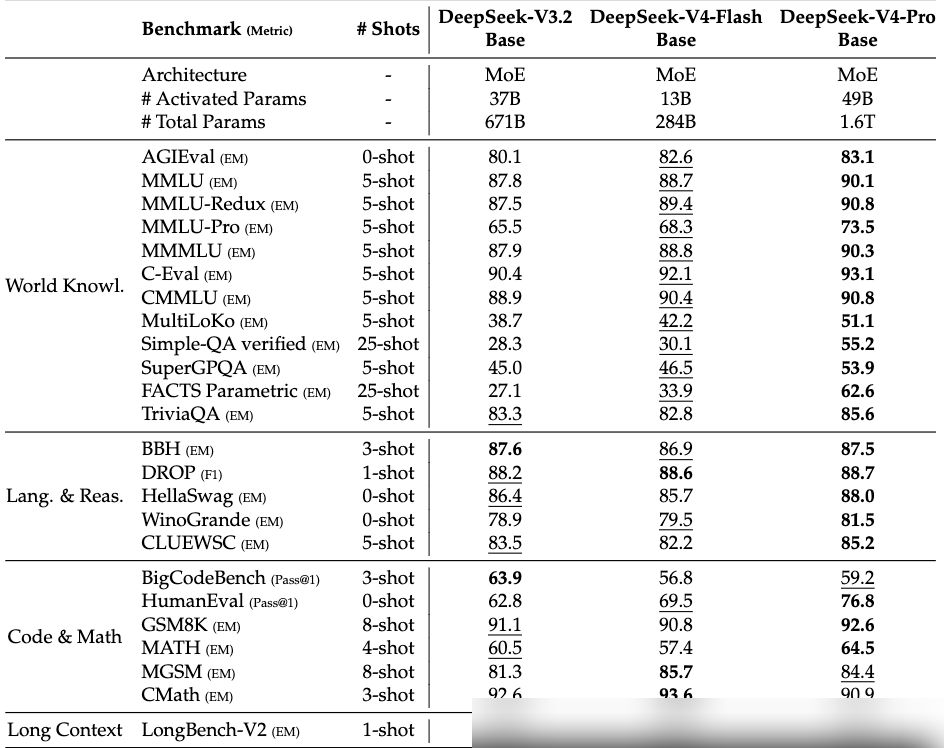
Architectural Innovations for 1M Context
To process 1M tokens efficiently, DeepSeek V4 introduces significant modifications to the attention mechanism.
Since traditional attention computational complexity increases quadratically with sequence length, V4 employs a system that alternates between two types of compressed attention:
- CSA (Compressed Sparse Attention): Compresses the KV cache of $m$ tokens into one and uses sparse attention to select only $k$ of them for computation.
- HCA (Hierarchical Compressed Attention): Uses a higher compression rate to condense longer intervals while maintaining dense attention.
Additionally, CSA features a "Lightning Indexer," which uses FP4 low-precision to rapidly calculate correlation scores between query tokens and compressed blocks. To ensure local details are not lost, both mechanisms incorporate a sliding window branch.
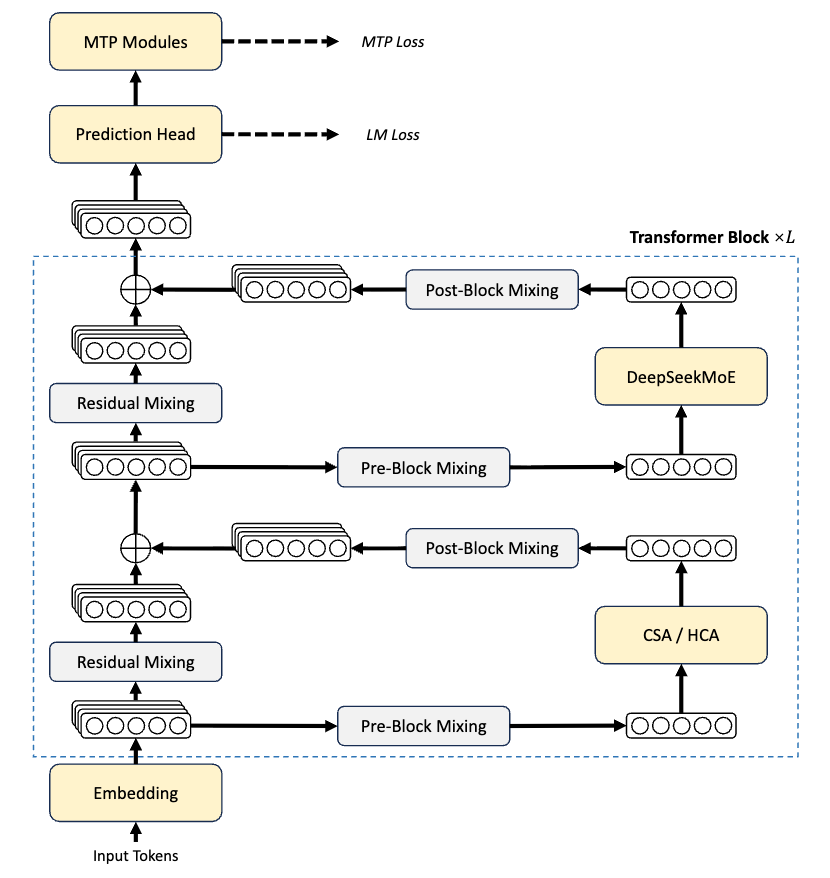
Consequently, for 1M context, the single-token inference computation for V4-Pro is only 27% of V3.2, and KV cache occupancy is reduced to 10%. V4-Flash is even more aggressive, reducing computation to 10% and KV cache to 7% compared to V3.2.
Training Optimization and Stability
To enhance residual connections, DeepSeek introduced "manifold Constrained Hyper-connection (mHC)" to stabilize signal transmission and optimize information propagation across layers. For optimization, they utilized the Muon optimizer to iteratively orthogonalize gradient matrices, improving convergence speed and stability. A hybrid approach is used, applying Muon for most tasks while retaining AdamW for the embedding layers and prediction heads.
To combat "Loss Spikes" during training, two measures were implemented:
- Anticipatory Routing: Decouples updates to break vicious cycles.
- SwiGLU Linear Component Clipping: Limits numerical ranges to $[-10, 10]$ to suppress anomalies.

The models were pre-trained on over 32T high-quality tokens, followed by SFT and GRPO (Group Relative Policy Optimization) reinforcement learning. Online Distillation (OPD) was then used to consolidate capabilities across domains into a single model.
Open Source Deployment
Four weighted versions are open-sourced and available via HuggingFace and ModelScope. They utilize FP8 Mixed precision for Base versions and a mix of FP4/FP8 for the instruction-tuned versions. Due to dynamic range differences, dequantization from FP4 to FP8 occurs without loss.
The API supports both OpenAI ChatCompletions and Anthropic interfaces. Users can simply switch the model parameter to deepseek-v4-pro or deepseek-v4-flash to begin.
Challenging the NVIDIA Monopoly: The "Domestic Chip" Strategy
Beyond the technical specifications, the most strategic aspect of DeepSeek V4 is its primary optimization for domestic Chinese hardware (Huawei Ascend) rather than NVIDIA GPUs.
By granting domestic chipmakers early access, DeepSeek is fostering an ecosystem where the algorithms are proprietary, the code is open-source, and the hardware is domestically produced.
NVIDIA CEO Jensen Huang recently signaled that DeepSeek's progress is a point of concern, specifically the risk that AI models optimized for Chinese hardware could proliferate globally, potentially establishing Chinese technology as a global standard.
The successful operation of a trillion-parameter model on Ascend chips provides a massive boost to China's computational resource ecosystem and is expected to accelerate adoption by other chipmakers like Cambricon and Hygon.
Loading...