Qwen3.7 Complete Guide: Max vs Plus Benchmarks, Pricing, and API Integration
What is Qwen3.7?
On May 20, 2026, Alibaba officially unveiled Qwen3.7-Max at the Alibaba Cloud Summit. Designed as a foundation model for the agent era, it goes beyond conversational AI — capable of writing and debugging code, automating office workflows, and sustaining autonomous execution across hundreds or thousands of steps.
The Qwen3.7 series includes two models:
| Model | Positioning | Availability |
|---|---|---|
| Qwen3.7-Max | Flagship. Strongest agent capabilities | API only (closed-source) |
| Qwen3.7-Plus | High-performance balanced variant | API only (closed-source) |
Unlike Qwen3.6-27B and Qwen3.6-35B-A3B which are open-source under Apache 2.0, the 3.7 series is currently available only via API.
Arena AI Rankings
Qwen3.7-Max-Preview appeared on Arena AI (formerly LMArena) on May 19, 2026, immediately drawing attention.
Text Overall Ranking: #13 (between GPT 5.5 and Grok 4.2), #1 among domestic (Chinese) models
Vision Ranking: Qwen3.7-Plus-Preview at #16
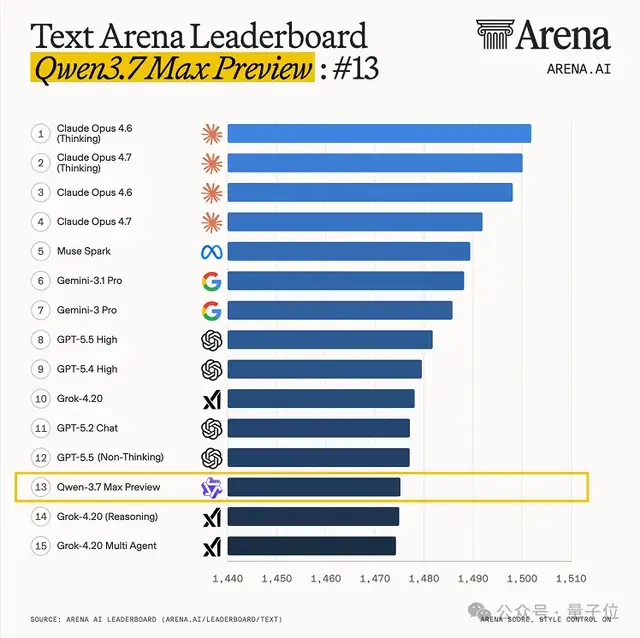
According to Artificial Analysis, Qwen3.7-Max scored 56.6 overall — approaching GPT, Claude, and Gemini's strongest models, ranking #1 domestically and #5 globally.
Detailed Benchmark Scores
BenchLM Overall Assessment
Per BenchLM.ai, Qwen3.7-Max scored 92/100 overall, ranking #3 of 117 models. Arena Elo: 1475.
| Category | Score | Ranking |
|---|---|---|
| Coding | 92.2 | #4 |
| Reasoning | 96.4 | — |
| Agentic | 87.7 | — |
| Knowledge | 86.8 | #9 |
| Multilingual | 88.2 | #10 |
| Instruction Following | 93.6 | #7 |
Arena Elo Breakdown
| Category | Elo | Votes |
|---|---|---|
| Text Overall | 1475 | 3,741 |
| Coding | 1525 | 1,135 |
| Math | 1499 | 218 |
| Hard Prompts | 1496 | 2,546 |
| Multi-turn | 1484 | 648 |
Head-to-Head: Qwen3.7 vs Claude, GPT, DeepSeek
Coding Agents
| Benchmark | Qwen3.7-Max | Claude Opus 4.6 | DeepSeek V4 Pro | GPT-5.5 |
|---|---|---|---|---|
| SWE-Pro | 60.6 | — | — | — |
| SWE-Multilingual | 78.3 | — | — | — |
| SWE-Verified | 80.4 | 80.8 | 80.6 | — |
| Terminal-Bench 2.0 | 69.7 | — | 67.9 | — |
| SciCode | 53.5 | — | — | — |
On SWE-Verified, Qwen3.7-Max (80.4) is on par with Claude Opus 4.6 Max (80.8) and DeepSeek V4 Pro Max (80.6). On Terminal-Bench 2.0, it outperforms DeepSeek V4 Pro Max (67.9).
General-Purpose Agents
| Benchmark | Qwen3.7-Max | Claude Opus 4.6 | GLM 5.1 | Kimi K2.6 |
|---|---|---|---|---|
| MCP-Mark | 60.8 | — | 57.5 | — |
| MCP-Atlas | 76.4 | 75.8 | — | — |
| SkillsBench | 59.2 | — | — | 56.2 |
| BFCL-V4 | 75.0 | — | — | — |
| SpreadSheetBench-v1 | 87.0 | — | — | — |
| Kernel Bench L3 | 1.98x / 96% | — | — | — |
MCP-Atlas: edges out Claude Opus 4.6 (75.8). SkillsBench: surpasses Kimi K2.6 (56.2).
Reasoning
| Benchmark | Qwen3.7-Max | Claude Opus 4.6 | DeepSeek V4 Pro |
|---|---|---|---|
| GPQA Diamond | 92.4 | 91.3 | — |
| HLE | 41.4 | 40.0 | — |
| HMMT 2026 Feb | 97.1 | 96.2 | — |
| IMOAnswerBench | 90.0 | — | 89.8 |
| Apex | 44.5 | — | 38.3 |
Qwen3.7-Max consistently outperforms Claude Opus 4.6 on reasoning benchmarks. GPQA Diamond 92.4 is among the highest publicly reported scores.
General Capabilities & Multilingual
| Benchmark | Qwen3.7-Max | DeepSeek V4 Pro |
|---|---|---|
| IFBench | 79.1 | 77.0 |
| WMT24++ | 85.8 | — |
| MAXIFE | 89.2 | — |
| SuperGPQA | 73.6 | — |
The 35-Hour Experiment: The Most Important Result
Beyond benchmark scores, the most striking achievement is Qwen3.7-Max's 35-hour fully autonomous optimization task.
The Task
Alibaba tasked Qwen3.7-Max with optimizing an inference kernel on the T-Head ZW-M890 — a chip the model had never seen during training. No hardware documentation, no profiling data, no example kernels were provided. Only a task description, the existing SGLang implementation, and an evaluation script.
Results
- Duration: 35 hours continuous (zero human intervention)
- Tool calls: 1,158
- Kernel evaluations: 432
- Outcome: 10.0x geometric mean speedup over the Triton reference
The model maintained a coherent optimization strategy throughout. After 30+ hours, it was still finding meaningful improvements — demonstrating that long-horizon autonomous optimization is not just feasible but productive.
Comparison with Other Models
| Model | Speedup | Notes |
|---|---|---|
| Qwen3.7-Max | 10.0x | Completed 35 hours |
| GLM 5.1 | 7.3x | — |
| Kimi K2.6 | 5.0x | — |
| DeepSeek V4 Pro | 3.3x | Stopped early |
| Qwen3.6-Plus | 1.1x | Stopped early |
Models that stopped early did so because they issued no tool calls for five consecutive rounds — the model itself concluded it could no longer make progress.
KernelBench L3
On KernelBench L3, Qwen3.7-Max produced accelerated kernels for 96% of scenarios:
| Model | Accelerated Kernel Rate |
|---|---|
| Claude Opus 4.6 | 98% |
| Qwen3.7-Max | 96% |
| GLM 5.1 | 78% |
| Kimi K2.6 | 80% |
| DeepSeek V4 Pro | 54% |
YC-Bench: Startup Management Simulation
Qwen3.7-Max also excelled at YC-Bench, which simulates a full year-long startup lifecycle requiring hundreds of decisions across personnel management, contract screening, and malicious client identification.
| Model | Total Revenue | Tasks Completed |
|---|---|---|
| Qwen3.7-Max | $2.08M | 237 |
| Qwen3.6-Plus | $1.05M | — |
| Qwen3.5-Plus | $352K | — |
Qwen3.7-Max achieved 2x the revenue of its predecessor and 6x of the generation before that.
API Pricing
Qwen3.7-Max is available via Alibaba Cloud Model Studio.
| Item | Price |
|---|---|
| Input tokens | $2.50 / 1M tokens |
| Output tokens | $7.50 / 1M tokens |
| Context window | 1M tokens |
This is significantly cheaper than Claude Opus 4.6 ($15 input / $75 output) — roughly 1/6 the input cost and 1/10 the output cost.
API Integration
OpenAI-Compatible API
from openai import OpenAI
client = OpenAI(
api_key="your-dashscope-api-key",
base_url="https://dashscope-intl.aliyuncs.com/compatible-mode/v1"
)
completion = client.chat.completions.create(
model="qwen3.7-max",
messages=[{"role": "user", "content": "Write a Python function to merge two sorted linked lists."}],
extra_body={"enable_thinking": True},
stream=True
)
Claude Code Integration
Qwen APIs support the Anthropic API protocol, enabling direct use with Claude Code:
export ANTHROPIC_MODEL="qwen3.7-max"
export ANTHROPIC_SMALL_FAST_MODEL="qwen3.7-max"
export ANTHROPIC_BASE_URL=https://dashscope-intl.aliyuncs.com/apps/anthropic
export ANTHROPIC_AUTH_TOKEN=<your_api_key>
claude
OpenClaw Integration
curl -fsSL https://molt.bot/install.sh | bash
export DASHSCOPE_API_KEY=<your_api_key>
openclaw dashboard
Qwen Code
npm install -g @qwen-code/qwen-code@latest
qwen
The preserve_thinking Feature
Qwen3.7-Max supports preserve_thinking, which retains thinking content from all preceding turns in messages. This is recommended for agentic tasks where maintaining reasoning consistency across long multi-turn conversations is critical.
Qwen Release Timeline
Qwen3.7-Max arrived as the third consecutive monthly flagship release:
| Date | Model | Theme |
|---|---|---|
| Feb 2026 | Qwen3.5-Max | Native multimodal agent |
| Mar 30, 2026 | Qwen3.5-Omni | Full-modality support |
| Apr 2, 2026 | Qwen3.6-Plus | Agent programming enhancement |
| Apr 16, 2026 | Qwen3.6-35B-A3B | MoE open-source |
| Apr 22, 2026 | Qwen3.6-27B | Dense model open-source |
| May 20, 2026 | Qwen3.7-Max | Agent era benchmark |
This monthly cadence of flagship releases is unprecedented in the industry.
Conclusion
Qwen3.7-Max represents Alibaba's most capable model for agent-driven workflows. Key takeaways:
- Arena #1 domestic, #5 global — approaching GPT, Claude, Gemini
- Reasoning: GPQA Diamond 92.4, surpassing Claude Opus 4.6 (91.3)
- Coding: SWE-Pro 60.6, Terminal-Bench 69.7
- 35-hour autonomous experiment: 1,158 tool calls, 10x speedup
- Pricing: $2.50/$7.50 per 1M tokens (~1/10 of Claude Opus)
- Context: 1M tokens
- Integration: Claude Code, OpenClaw, Qwen Code supported
In the agent era, Qwen3.7-Max sets a new standard — not just for being smart, but for being able to work autonomously for extended periods without losing coherence.
Loading...