NVIDIA RTX Spark Unveiled: Redefining the Personal Computer with Unified Memory and CUDA
A New Era for the PC: NVIDIA GTC Taipei 2026
NVIDIA GTC Taipei 2026 kicked off today at 11:00 AM local time. Among a wave of announcements, one product stands out as a historical milestone. NVIDIA didn't mince words, declaring that as we mark the 40th anniversary of the personal computer, they are here to "redefine" it.
"A New Line, A New Beginning."
It all starts with a brand new consumer chip—the long-leaked "N1X" codenamed RTX Spark.
 — alt: "RTX Spark"
— alt: "RTX Spark"
This small device is the core of the most anticipated AI conference of the first half of the year. It is rare to see multiple industry giants coordinate their momentum so precisely to converge on a single reveal.
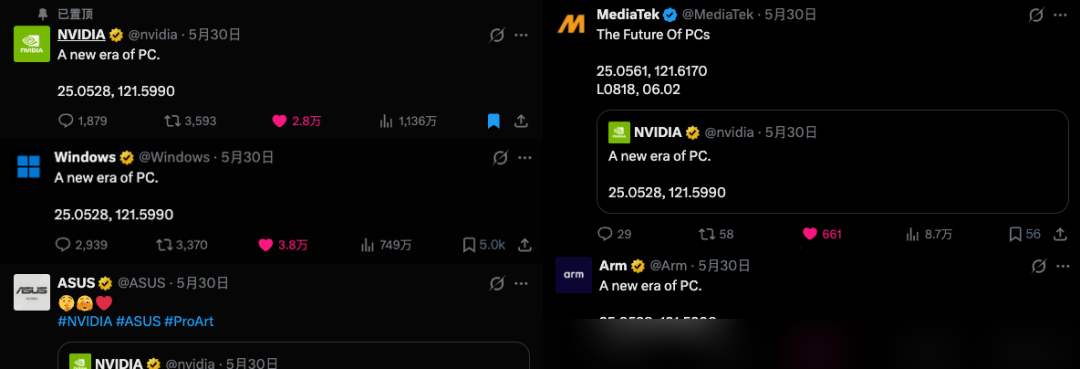 — alt: "Key Visual"
— alt: "Key Visual"
Only NVIDIA could assemble a lineup for a "new era of the PC" with this much gravitas. The cryptic coordinates seen in the marketing materials refer to the Taipei Pop Music Center, where Jensen Huang delivered his keynote.
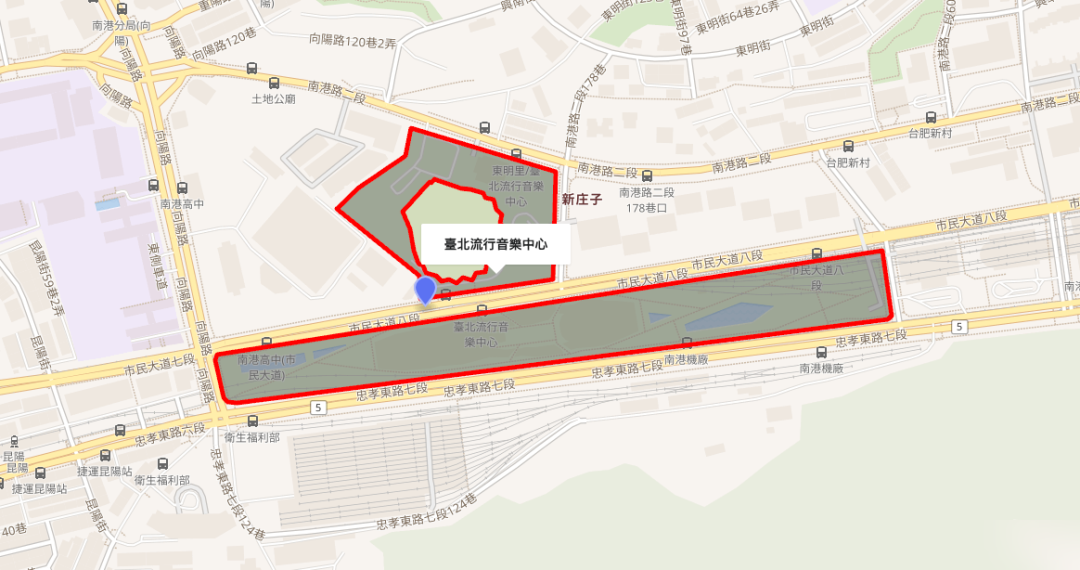 — alt: "Taipei Pop Music Center"
— alt: "Taipei Pop Music Center"
Having witnessed the presentation, it's hard not to believe in the promise of a new era for personal computing.
Much of AI progress in early 2024—OpenClaw, Claude Code, Codex—has been dominated by massive cloud-based models. However, consumer hardware has largely stagnated. Yet, the desire to deploy Large Language Models (LLMs) and AI Agents locally is universal. Low latency, guaranteed privacy, and offline autonomy—combined with the freedom to perform not just inference but actual fine-tuning—remain incredibly alluring.
We needed new hardware. We needed a new chip. And we needed a bolder vision. RTX Spark is the answer we've been waiting for.
 — alt: "RTX Spark Exterior"
— alt: "RTX Spark Exterior"
For those familiar with NVIDIA, the terms "RTX" and "Spark" are already known. RTX is the staple of consumer graphics (like the RTX 5080), while Spark originates from the developer-focused DGX Spark. Now, NVIDIA has evolved Spark into a full-fledged consumer business line, giving birth to the RTX Spark.
RTX Spark Specs and Potential
RTX Spark is based on the GB10 chip, similar to the DGX Spark. The flagship specs announced align closely with previous industry leaks.
 — alt: "RTX Spark Specs Table"
— alt: "RTX Spark Specs Table"
Key specifications include up to 1 PFLOPS of AI performance (FP4), a 20-core CPU, 6144 GPU cores, and 128GB of LPDDR5X Unified Memory. This allows the device to run 120B parameter models locally with ease.
During the keynote, Jensen Huang revealed concept PCs from partner brands powered by RTX Spark.
 — alt: "RTX Spark Laptop Concept"
— alt: "RTX Spark Laptop Concept"
Imagine a laptop only 14mm thick, running on battery, capable of rendering 90GB 3D scenes and editing 12K resolution video. The performance metrics are staggering.
Beyond ultra-thin high-performance laptops, we will also see low-power, small-form-factor boxes similar to the Mac Mini.
 — alt: "Compact Desktop Terminal"
— alt: "Compact Desktop Terminal"
This explains the recent surge in interest around Lenovo, HP, and Arm. For the first time in the PC market, we have a unified memory architecture that is ultra-fast and fully compatible with the CUDA ecosystem, enabling the local execution of massive AI models.
Furthermore, Microsoft and NVIDIA are partnering to rebuild the Windows system so that RTX Spark-powered PCs can run local Agents natively. The Windows ecosystem is being revitalized—with NVIDIA acting as the catalyst. This truly isn't just marketing fluff; we are likely looking at a massive hardware refresh cycle for Windows users next year.
How Unified Memory Changes Local AI
To understand the historical significance of RTX Spark, one must understand "Unified Memory."
Traditional PCs rely on two core components: the CPU and the GPU.
 — alt: "CPU Diagram"
— alt: "CPU Diagram"
As most know, the GPU usually exists as a discrete graphics card—such as the RTX 5080 I use in my own rig.
 — alt: "Author's RTX 5080"
— alt: "Author's RTX 5080"
In a traditional setup, the CPU and GPU have separate memory pools. The CPU uses system RAM, and the GPU uses dedicated Video RAM (VRAM). Data must travel between them through a specific channel.
Unified Memory merges these two into a single pool, allowing both the CPU and GPU to access the same memory space directly. Apple pioneered this approach, and it is now standard across nearly all modern Macs.
 — alt: "Mac Unified Memory"
— alt: "Mac Unified Memory"
In the Windows ecosystem, however, CPUs and GPUs are often made by different vendors. Past attempts to unify memory failed due to ecosystem fragmentation. NVIDIA is the first to successfully orchestrate the entire supply chain to push this forward at scale.
For LLMs, this is the difference between a model that works and one that doesn't.
In a traditional architecture, the CPU and GPU are connected via the PCIe interface.
 — alt: "Traditional Memory Configuration"
— alt: "Traditional Memory Configuration"
Imagine a PC with 64GB of RAM and an RTX 5080 with 16GB of VRAM. Running a quantized 70B model requires dozens of gigabytes of memory. While the PC has 64GB total, the GPU can only access its 16GB VRAM at high speed. If the model exceeds 16GB, the remaining weights must sit in system RAM. Every time the GPU needs those weights, it must fetch them across the PCIe bus.
While VRAM access operates at roughly 1TB/s, the PCIe 4.0 x16 lane is limited to about 32GB/s—a 30x difference. It's like moving from a supercar to a snail. Consequently, the model either crashes or runs at an unusable crawl.
Unified Memory solves this. By integrating memory into a shared pool—say, 128GB—the GPU can directly utilize the vast majority of that space. This removes the crippling 16GB, 24GB, or 32GB VRAM limits of discrete cards. For a single consumer machine, unified memory is the most elegant solution for running massive local models.
The CUDA Ecosystem: The Ultimate Moat
This raises a logical question: If unified memory is so great, why not just buy a Mac with 128GB of RAM? Why do we need RTX Spark?
The answer lies in NVIDIA's true "killer feature": CUDA.
 — alt: "CUDA Logo"
— alt: "CUDA Logo"
To the uninitiated, CUDA is often seen as just a driver or a GPU acceleration technology. While technically true, CUDA is something far larger: it is the ultimate ecosystem.
 — alt: "CUDA Ecosystem"
— alt: "CUDA Ecosystem"
At its base, CUDA allows the GPU to function as a general-purpose computer, performing complex mathematical operations beyond simple rendering.
In the middle layer are nearly two decades of polished math libraries: cuBLAS for linear algebra, cuDNN for deep learning primitives, TensorRT for inference optimization, and NCCL for multi-GPU communication. Critical innovations like FlashAttention are always most mature on CUDA and are prioritized for NVIDIA hardware.
Jensen Huang emphasized CUDA-X—a suite of CUDA libraries now open to AI Agents, allowing them to call these libraries directly.
 — alt: "CUDA-X"
— alt: "CUDA-X"
This includes acceleration for scientific computing, engineering simulation, chip design, genomics, robotics, and physics. Libraries like cuLitho for computational lithography, cuOpt for decision optimization, and Parabricks for genomics are all part of this powerhouse.
 — alt: "CUDA Libraries"
— alt: "CUDA Libraries"
As Jensen puts it: "Math is beautiful. CUDA is powerful."
At the top level, almost every deep learning framework—PyTorch, TensorFlow, JAX—supports CUDA as the default, primary backend. Since 2006, a massive mountain of optimization libraries, tutorials, and open-source code has been built on CUDA. The vast majority of academic papers provide code written and tested on CUDA. In the world of AI engineering, CUDA is the native language.
This has been Apple's Achilles' heel. Apple has great unified memory, but it uses Metal and the MLX framework. Most open-source models and fine-tuning tools are built for CUDA first and ported to MLX much later. While inference is viable on Mac, the ecosystem for training and fine-tuning remains fragile.
This is why RTX Spark is so anticipated. Before now, you had to choose: you could have CUDA (Discrete GPU) or you could have Unified Memory (Mac). You couldn't have both on one platform.
RTX Spark fuses these two incompatible worlds. It provides the memory scale needed for LLMs and the software ecosystem needed for AI development. This is the definitive differentiator.
Building the Foundation for the Windows Agent Era
With the CUDA ecosystem as a foundation, partners like Adobe are already optimizing. Adobe is redesigning the core architecture of Photoshop and Premiere for RTX Spark, promising up to 2x speed increases and native support for AI Agent calls.
 — alt: "Adobe Optimization"
— alt: "Adobe Optimization"
Meanwhile, NVIDIA and Microsoft are rebuilding the Agent ecosystem on Windows. While more details will come in a live chat with Satya Nadella, the blueprint is already visible.
New Windows security primitives will provide identity authentication, isolation, and policy management for the native construction and execution of Agents. Additionally, NVIDIA is introducing OpenShell.
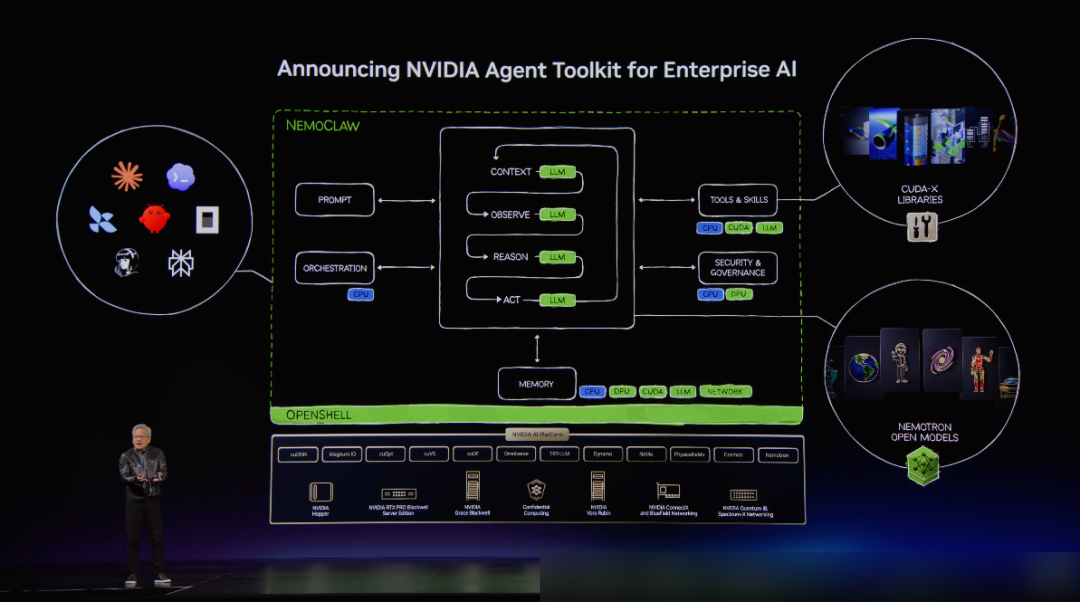 — alt: "NVIDIA OpenShell"
— alt: "NVIDIA OpenShell"
The full vision for the Agent-ready PC is now clear:
- Hardware Layer: RTX Spark providing massive compute and unified memory.
- OS Layer: An evolved Windows system designed for Agents.
- Execution Layer: Secure environments combining Windows security primitives and NVIDIA OpenShell.
For developers and creators who want to run massive models locally, an RTX Spark machine is now the optimal choice. And if you want to play AAA games on the side? There is no other option. RTX Spark is it.
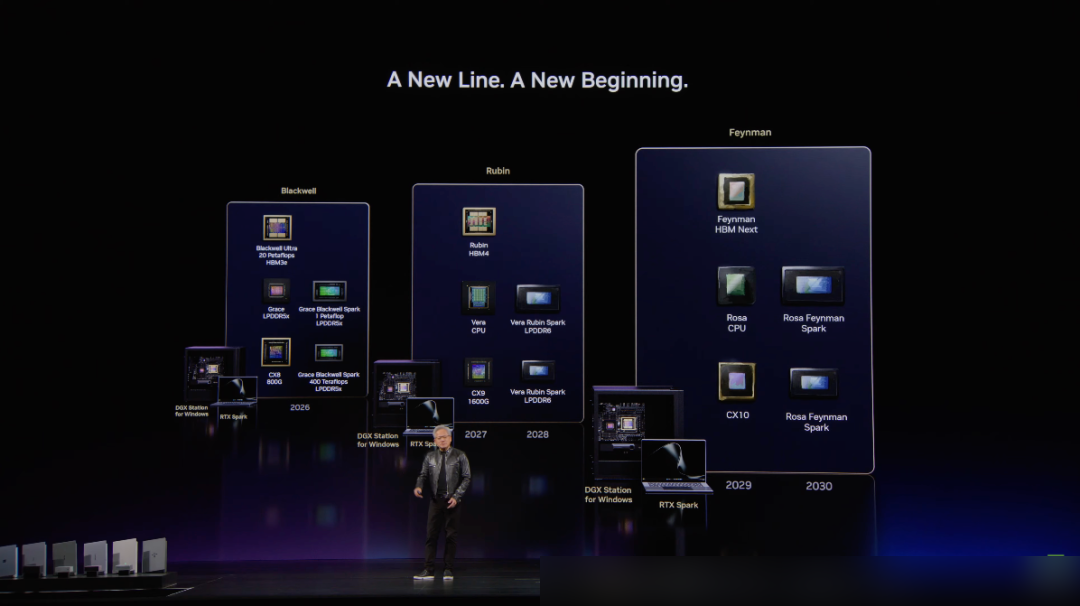 — alt: "New Era Visual"
— alt: "New Era Visual"
A New Line, A New Beginning.
This is the new era of the personal computer—designed not just for humans, but for the Agents that will assist them. It carries the compatibility of the past to step boldly into the future.
Loading...