World Models Explained: The Next Frontier Beyond LLMs
Recently, the AI world has witnessed a fascinating shift in focus. Turing Award winners Yann LeCun and Xie Saining co-founded AMI Labs, securing a $1 billion investment not to build bigger LLMs, but to create a "world model." Almost simultaneously, Fei-Fei Li's World Labs raised hundreds of millions, focusing on "spatial intelligence"—helping AI understand the 3D world, not just chat and create images. With DeepMind's Demis Hassabis also backing Genie, some of AI's most prominent names are converging on the same path.
This path is the World Model.
It tackles a problem entirely different from LLMs: an LLM tells you "what the world is like," while a world model tells you "what the world will become if I do this." One is an observer; the other is a participant.
Recently, Datawhale launched an open-source project called learn-world-model, aiming to guide everyone from zero to understanding and building world models. This article serves as an introductory guide.
 Open-source address: https://github.com/datawhalechina/learn-world-model/tree/main
Open-source address: https://github.com/datawhalechina/learn-world-model/tree/main
We'll avoid jargon and equation bombs. First, we'll clarify what it is, then walk through its 80-year history, and finally dissect the five hottest technical approaches.
This lineage actually starts much earlier than LLMs. As far back as 1943, British psychologist Kenneth Craik hypothesized that the brain maintains a "small-scale model of reality," running simulations before acting. Eighty years later, these titans are bringing it to life in their own ways.
First, A Story: The Brain is a "Prediction Machine"
Neuroscience discovered something intriguing in the 1990s: the brain doesn't passively "see" the world; it actively predicts the world and only processes the "prediction errors."
This is called Predictive Coding.
The visual cortex doesn't faithfully transmit every pixel received from the eyes—too energy-intensive. Higher brain layers continuously send "predictions" down to lower layers, which only report the error between prediction and actual sensory input.
When you walk into a familiar office, your brain processes almost nothing because everything is as expected. But if your colleague's chair is in a different spot, that "error" signal immediately grabs your attention. Accurately predicted parts are compressed away; only errors are worth the metabolic resources.
Control engineering independently discovered a similar principle in the 1960s, called the Internal Model Principle:
To achieve perfect control over a system, the controller must contain a model of that system.
To control something, you must first understand it. This principle underpins robotics, spacecraft, and autonomous driving, and later became the theoretical foundation for model-based reinforcement learning.
What Exactly is a World Model? (This One Formula is Enough)
The term is often used loosely; let's define its boundaries.
Broadly speaking: Any model that can predict "what will happen next" can be called a world model. Video generation models predict the next frame, language models predict the next word, weather forecasts predict tomorrow's temperature—all qualify.
Narrowly speaking, in reinforcement learning and robotics, a world model has a stricter meaning: it must be conditioned on an action. It's not just "what the next frame looks like," but rather:
"How will the world change after I take this action?"
In one sentence: given the current observation and an action, predict the probability distribution of the observation at the next time step.
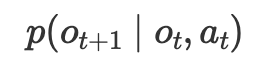
Where $o_t$ is the current observation, $a_t$ is the executed action, and $o_{t+1}$ is the next observation.
With this single condition, the world model transforms from an "observer" to a "participant": it doesn't just tell you how the world will be, but also what the consequences of your choices will be. Robots specifically need the latter.
This article focuses on this stricter definition.
What Can a World Model Do? Three Irreplaceable Values
Three key values. The first is most intuitive; the next two are what industry truly cares about, and are often overlooked.
Value 1: Sample Efficiency — Practice 10,000 Times in Your Head
Model-Free reinforcement learning requires millions of real-world interactions to learn a simple task, with each interaction consuming real time and resources.
A world model allows an agent to "virtually experience" massive amounts of trajectories through internal simulation:
Dreamer V3 (arXiv:2301.04104) surpassed human performance on the Atari 100k benchmark (allowing only 100,000 real environment steps), relying precisely on this mechanism.
Value 2: Planning Capability — Calculate Before You Act
With a world model, an agent can mentally simulate multiple paths before acting, choosing the one with the highest expected reward.
MuZero (DeepMind, 2020, arXiv:1911.08265) used this mechanism to learn an internal dynamics model without being told the game rules (state transition equations, terminal conditions), and mastered universal strategies for Chess, Go, and Atari games.
Value 3: Safety — The Killer Feature Industry Values Most
In robotics, autonomous driving, and industrial control, the cost of trial and error can be catastrophic.
The world model's solution:
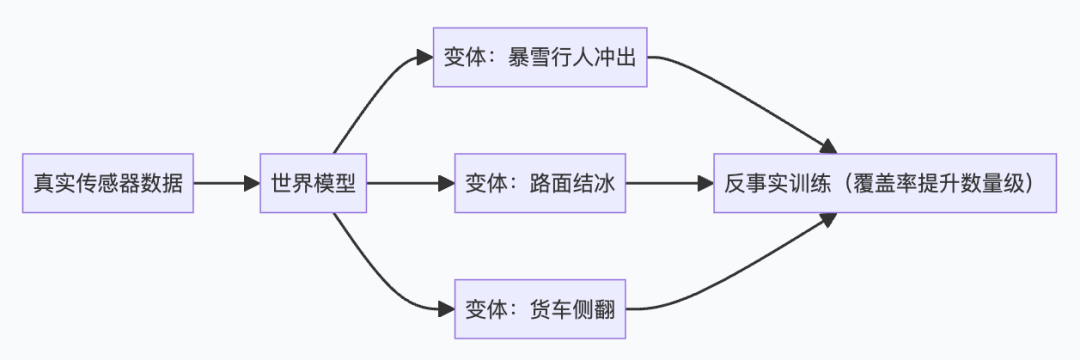 Wayve's GAIA-1 (arXiv:2309.17080) has validated this approach at an industrial scale: given real driving footage, the model can automatically generate variants of the same intersection with different weather/pedestrian behaviors, increasing training coverage for safety-critical scenarios to a scale impossible with pure real-world data collection, at a fraction of the cost.
Wayve's GAIA-1 (arXiv:2309.17080) has validated this approach at an industrial scale: given real driving footage, the model can automatically generate variants of the same intersection with different weather/pedestrian behaviors, increasing training coverage for safety-critical scenarios to a scale impossible with pure real-world data collection, at a fraction of the cost.
A Brief History: From 1943 to 2026, Four Eras
Era 1: Theoretical Foundations (1950s–2017)
Recurrent Neural Networks (RNNs), Kalman filters, Hidden Markov Models... For seventy years, researchers in control theory, speech recognition, and robotics built tools for "predicting future states" in different corners, never collectively called "world models."
A prime example: the Kalman filter helped the Apollo navigation system predict spacecraft position in real-time in the 1960s. Instead of waiting for sensor readings, it used an internal model to "guess" where the spacecraft would be in the next second, then corrected the error with actual measurements. This same logic later appeared in speech recognition, weather forecasting, and industrial robots, just in different mathematical attire.
It wasn't until 2018 that a paper first assembled these scattered tools into an end-to-end trainable framework.
Era 2: "Learning to Drive in a Dream" (2018)
In 2018, David Ha and Jürgen Schmidhuber published "World Models" (arXiv:1803.10122), constructing the framework with three modules:
 The V module is a convolutional neural network that compresses each game frame into a low-dimensional vector z. The M module is a Mixture Density Network + RNN (MDN-RNN), taking z and the previous action as input to predict the probability distribution of the next z. The C module is a simple linear layer that maps the current z and hidden state to an action.
The V module is a convolutional neural network that compresses each game frame into a low-dimensional vector z. The M module is a Mixture Density Network + RNN (MDN-RNN), taking z and the previous action as input to predict the probability distribution of the next z. The C module is a simple linear layer that maps the current z and hidden state to an action.
Their most fascinating experiment: they placed the controller inside a virtual environment hallucinated by the memory module for training, then transferred the policy to the real game. Learn to drive in a dream, and you can hit the road upon waking. This metaphor brought world models into the public eye for the first time.
However, the experiment also exposed a core challenge: the controller learned to exploit errors in the world model to generate fake high scores—cheating in the dream rather than learning real skills. In RL, this is known as reward hacking. The model hadn't learned to drive yet, but had already learned to game the KPIs. This problem has since become a central challenge the entire field continually strives to overcome.
Era 3: The Latent Space Revolution (2019–2022)
In 2019, Danijar Hafner et al. introduced Dreamer V1 (arXiv:1912.01603), introducing the RSSM (Recurrent State-Space Model), pushing world model architecture to a new level.
Dreamer's core change was singular: stop doing anything in pixel space. The entire pipeline of prediction, planning, and reward learning happens directly in a low-dimensional latent space.
What is latent space? Compress a 64×64 game frame (12,288 pixel values) into a vector of just a few dozen dimensions, discarding irrelevant details like lighting, textures, and background noise, keeping only structural information like "there's a platform here, an enemy there." This compressed, low-dimensional space is the latent space. The network performing the compression is a VAE (Variational Autoencoder), trained so that reconstructing from the compressed code closely resembles the original.
Why is this change so critical? Predicting in pixel space requires the model to be responsible for the precise values of 12,288 numbers, including every background pixel of noise and every subtle change in lighting, demanding immense computational power.
RSSM splits this problem into two parallel paths. A deterministic path uses a GRU (a type of RNN unit good at remembering "what has happened so far") to capture smooth, continuous dynamics. A stochastic path samples a random vector from a learned probability distribution to capture genuine environmental uncertainty, like whether a thrown ball will bounce into a hole. The two paths are concatenated before making the next prediction:
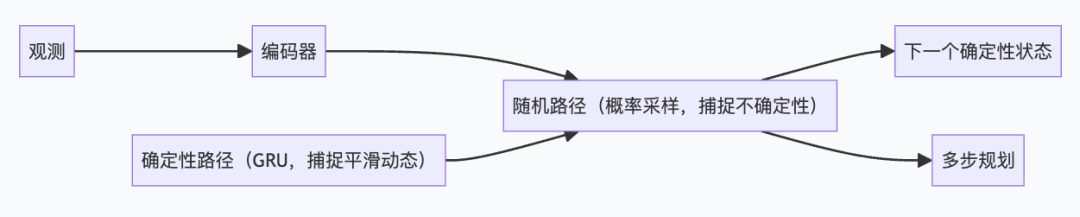 With this structure, Dreamer plans by feeding the current state into the RSSM, rolling out predictions for several future steps internally without interacting with the real environment, scoring them with a learned reward model, selecting the action sequence with the highest expected cumulative reward, and executing the first step. The entire "imagine-score-act" loop occurs in latent space, far faster than running in the real environment.
With this structure, Dreamer plans by feeding the current state into the RSSM, rolling out predictions for several future steps internally without interacting with the real environment, scoring them with a learned reward model, selecting the action sequence with the highest expected cumulative reward, and executing the first step. The entire "imagine-score-act" loop occurs in latent space, far faster than running in the real environment.
The Dreamer series evolved from V1 to V4, becoming the flagship work in the world model field. Dreamer V3 (arXiv:2301.04104) used a single set of hyperparameters to span over 150 tasks across 8 domains including Atari, Minecraft, and robotics control, achieving competitive results in each—a feat never before accomplished.
The "cheating problem" from Era 2 was structurally mitigated within the RSSM architecture: policy learning occurs entirely in latent space, drastically reducing exploitable "holes." Later, V-JEPA 2 cut off shortcuts at the training mechanism level using EMA (discussed below).
Era 4: Video as the World (2023+)
Around 2023, two parallel paths converged: Could we use video itself to learn the physical laws of the world?
Path A: JEPA (Joint Embedding Predictive Architecture)
Yann LeCun's team took a path fundamentally different from diffusion models: abandoning pixel reconstruction, predicting only in semantic embedding space.
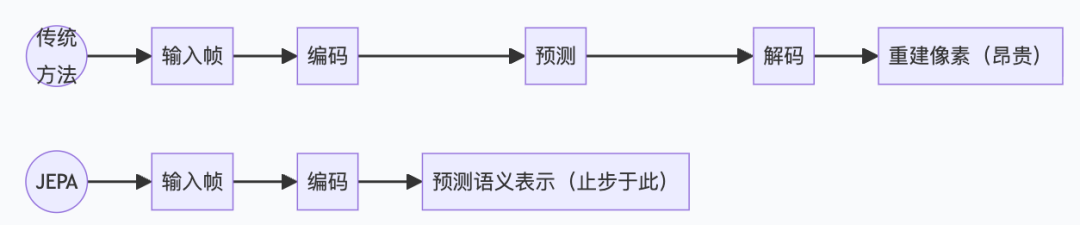 "I don't need to draw your face; I just need to know who you are."
"I don't need to draw your face; I just need to know who you are."
Meta's V-JEPA 2, released in 2025, is explicitly positioned as a "world model component towards AGI": given an action sequence, it predicts future visual representations in semantic space—not generating photorealistic video, but understanding "if I move my arm like this, where will the object be."
Path B: Large-Scale Video Generation
Google's Genie and Veo launched in 2024, followed by NVIDIA's Cosmos in early 2025. Researchers began asking: In the process of generating realistic video, do these models also learn spatial structure, object permanence, and coarse-grained physical laws? If so, could they serve as a foundational world model for robots?
This question remains unanswered definitively, but is serious enough to bring two previously parallel fields to the same discussion table.
Why the Surge in Just the Past Two Years?
Dreamer V1 from Era 3 was in 2019, and video generation in Era 4 started in 2023. Why did 2024–2025 become the highlight of every AI conference?
It wasn't a single breakthrough, but the simultaneous maturation of three independent threads.
Thread 1: Video Generation Suddenly Became Powerful. The emergence of Genie, Veo, and Cosmos (Era 4) dramatically improved video generation quality in a short time. But this quality boost raised a deeper question: high generation quality doesn't equal deep physical understanding. Can these models serve as a foundational world model for robots? This question spawned a surge in cross-disciplinary research, which is why world model discussions appeared in both video generation and robotics conferences after 2024.
Thread 2: Embodied Intelligence Hit a Data Bottleneck. Training general-purpose robots requires massive teleoperation data, which is prohibitively expensive. World models provide a workaround: learning indirectly from unlabeled videos.
Thread 3: Autonomous Driving Validated the Commercial Value of "Counterfactual Simulation." Wayve's GAIA-1 has already proven at an industrial scale that generating synthetic data for rare, dangerous scenarios with a world model is more efficient than simply accumulating test miles. The commercial logic of this path has been validated.
The last world model hype (2018–2020) was academia-led, proving feasibility in games with distant practical applications. This time (2024+), both industry and academia are entering the field because it has touched real cost bottlenecks and safety requirements.
Five Technical Approaches, Explained
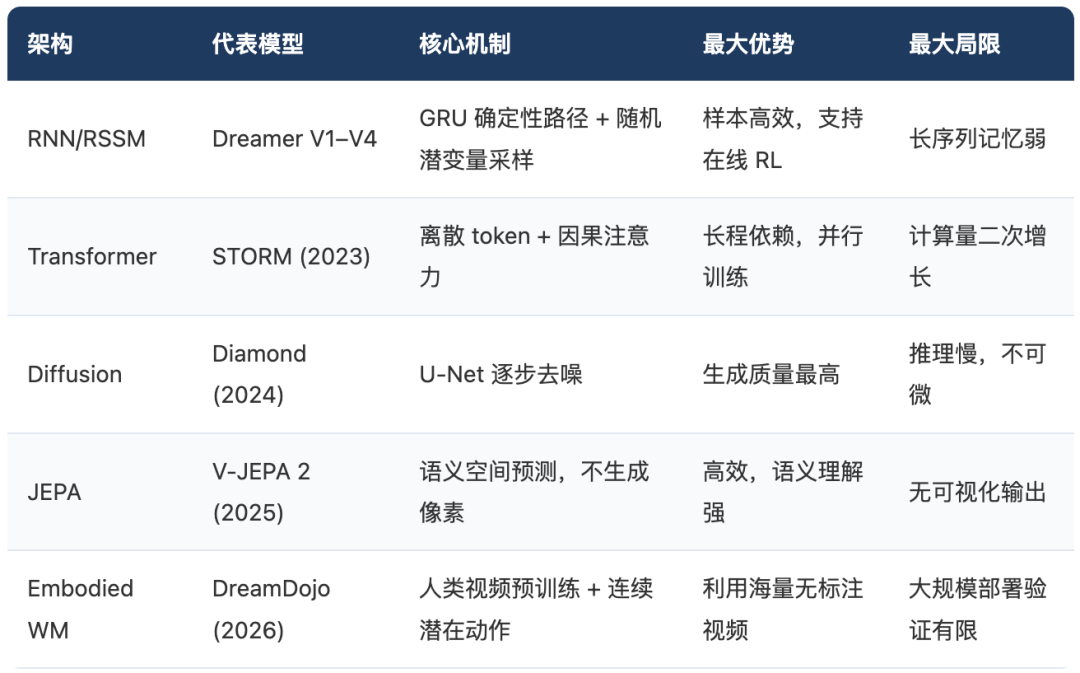
Post-2023, world models have diverged into five paths, each facing different core trade-offs: RNN/RSSM prioritizes sample efficiency, Transformers aim for long-range modeling, Diffusion models pursue generation quality, JEPA focuses on semantic understanding, and Embodied WM seeks data efficiency. The choice depends on which bottleneck your task is most sensitive to.
📊 Architecture Comparison at a Glance
STORM: Turning Game Frames into "Sentences"
STORM (NeurIPS 2023, arXiv:2310.09615) applies GPT's text-processing approach to video frames.
GPT can predict the "next word" because words are discrete and can be modeled with probability distributions. STORM uses a Categorical VAE to compress each frame into a discrete latent variable, like describing a musical phrase as "the A-section climax" instead of retaining "the complete waveform data for these 4 seconds." This discrete code is then merged with the current action into a single token for the Transformer to process.
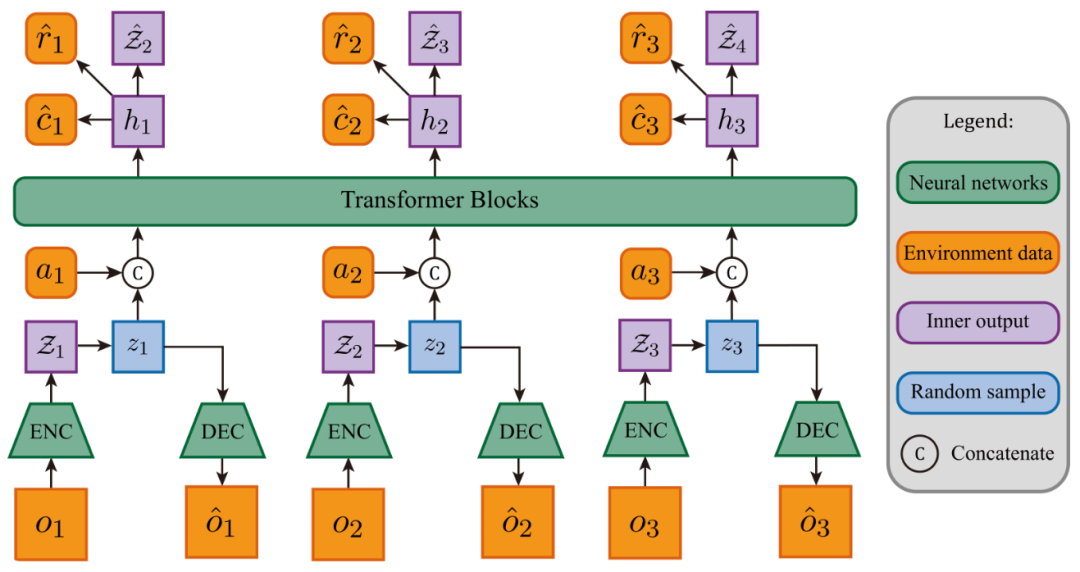 The single-token design drastically shortens sequence length (the contemporaneous IRIS method produced 16 tokens per frame, while STORM uses only 1), greatly speeding up training. On the Atari 100k benchmark, STORM set the record at the time for methods without additional planning algorithms with an average Human Normalized Score (HNS) of 126.7% (with human performance as 100%), requiring only about 4 hours on a single RTX 3090.
The single-token design drastically shortens sequence length (the contemporaneous IRIS method produced 16 tokens per frame, while STORM uses only 1), greatly speeding up training. On the Atari 100k benchmark, STORM set the record at the time for methods without additional planning algorithms with an average Human Normalized Score (HNS) of 126.7% (with human performance as 100%), requiring only about 4 hours on a single RTX 3090.
Diamond: "Painting" the Next Frame with Diffusion
Diamond (NeurIPS 2024, arXiv:2405.12399) took a different path: no discrete compression, instead using a diffusion model to gradually "denoise" into the next frame.
The core logic of a Diffusion Model is to first add noise to corrupt real images, then train a model to reverse the noise step by step. In the world model scenario, conditioned on historical frames and the current action, the denoised result of the diffusion model is the prediction of the next frame.
Diamond chose the rightmost approach: injecting action information into the U-Net via cross-attention, making the denoising process action-conditional:
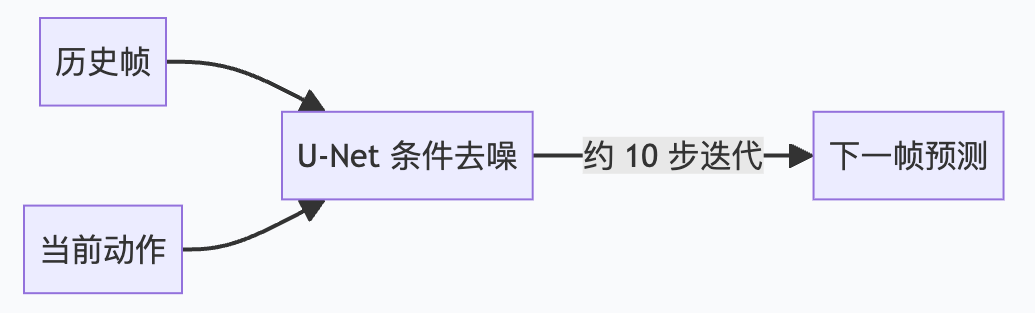
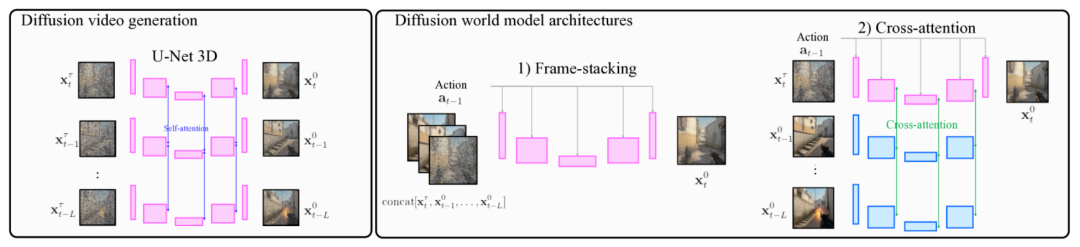
Diamond surpassed all previous world model methods on Atari 100k with an average HNS of 146%, and its generated video frames had the highest visual quality among the five architectures.
The trade-off: generating one frame requires multiple neural network forward passes, making computational overhead far higher than single-pass methods like STORM (measured frame generation throughput differs by roughly an order of magnitude); moreover, the generation process is non-differentiable, making it difficult to interface directly with policy optimization.
V-JEPA 2: No Painting, Only Understanding
V-JEPA 2 (Meta, 2025, arXiv:2506.09985) is the most "different": it doesn't generate images at all.
Its training objective is: given visible spatio-temporal patches from a video, predict the semantic representation of occluded patches, not pixel values. V-JEPA 2 further adds action conditioning, enabling the model to answer "how will the video's semantic representation change after executing this action sequence."
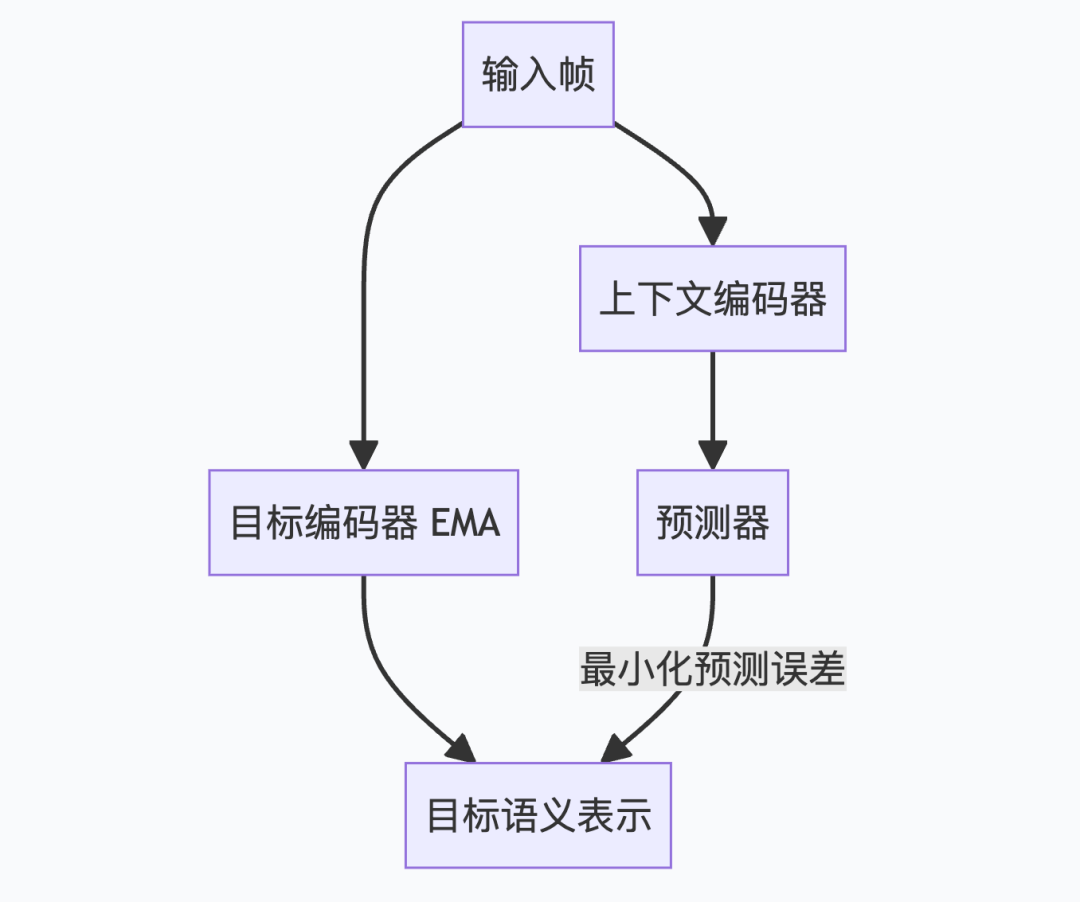
There's a pitfall here: if two encoders are updated in perfect sync, the model quickly finds a shortcut—mapping all inputs to the same vector minimizes prediction error, known as Representation Collapse. The key to blocking this shortcut is EMA (Exponential Moving Average): the target encoder's parameters don't follow gradients directly. Instead, they move slightly towards the other encoder at each step (e.g., retaining 99% of the old value, absorbing 1% of the new value), like a shadow always slightly delayed. Since they're never in sync, the model can't "cheat" by outputting a fixed vector.
V-JEPA 2 is explicitly positioned by Meta as a fundamental component for world models, not a video generator. Its advantage lies in structural understanding of the physical world: ignoring pixel-level details like lighting and texture, it models directly at the semantic level—"where is this object, is the hand holding it."
DreamDojo: "Stealing" Robot Skills from Human Videos
DreamDojo (NVIDIA, 2026, preprint, arXiv:2602.06949) addresses robotics' most practical problem: robot manipulation data is absurdly expensive.
Collecting high-quality robot teleoperation data requires specialized hardware, skilled operators, and real physical scenes, driving costs extremely high. However, the internet holds tens of thousands of hours of human daily operation videos (public datasets like Ego4D already exceed 44,000 hours), far exceeding the scale of robot teleoperation datasets.
DreamDojo's approach: first perform large-scale pre-training on these human videos to learn basic physical interaction laws (gravity, object collisions, hand motion patterns), then fine-tune on a small amount of robot data. Humans and robots have different morphologies, but the physical laws are the same—this is the premise for transfer.
How is the action labeling problem solved? Using Continuous Latent Actions as a proxy: automatically extracting a vector of a few dozen dimensions from the differences between adjacent frames, representing "what type of change occurred between frames." It's neither joint angles nor torque, but an abstract motion pattern automatically discovered by the model from video, bypassing the need for frame-by-frame manual annotation.
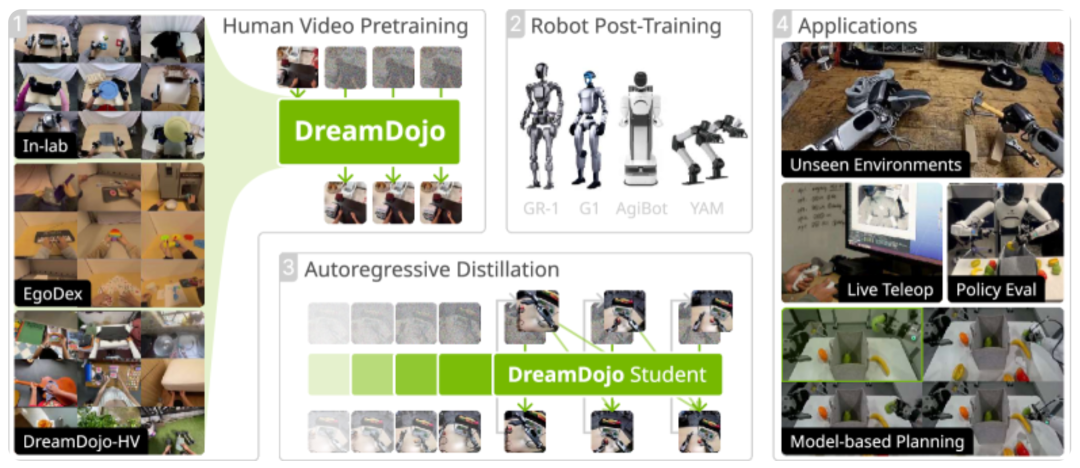 Ultimately, DreamDojo achieves an inference speed of 10.81 FPS at 640×480 resolution, meeting the basic requirements for real-time robot control, and demonstrates zero-shot generalization across different environments.
Ultimately, DreamDojo achieves an inference speed of 10.81 FPS at 640×480 resolution, meeting the basic requirements for real-time robot control, and demonstrates zero-shot generalization across different environments.
The Debate: Is the World Model Really the Right Answer?
Five architectures, five paths, each attracting investment, funding, and papers. But there's one question none of these papers answer: Is the world model truly the right direction? The AI field has three distinct voices on this, worth hearing separately.
Voice 1: The World Model is the Only Correct Path
This is Yann LeCun and Xie Saining's stance. AMI Labs, founded in December 2025 with LeCun as Executive Chairman and Xie as Chief Scientific Officer, had raised over $1 billion by March 2026. They explicitly target the Silicon Valley mainstream "centered on LLMs." Others raise billions to buy GPUs for training LLMs; they raise billions to prove everyone is training LLMs in the wrong direction.
Xie Saining's metaphor has circulated widely (from interview transcript):
"Language is a 'narcotic.' It's useful, but it's a shortcut. If you keep walking with a crutch, you can't train your thigh muscles."
LeCun's explanation is more detailed (see 2022 report "A Path Towards Autonomous Machine Intelligence"): LLMs process symbolic systems invented by humans—a secondary abstraction of the world. True intelligence needs to model the physical world directly from continuous sensory signals. His core assertion is: Representation is the most important part of a world model; language and pixels are just output interfaces for representation, not the foundation.
AMI Labs' technical choice is the non-generative JEPA path, predicting state transitions directly in semantic space without generating pixels. Their bet is that in five years, today's LLM-dominated landscape will be proven a detour.
Voice 2: LLMs Plus Multimodal Fusion is Sufficient
This is Google DeepMind's path. Demis Hassabis stated in a 2025 interview that Gemini's evolution is to "become a world model," but the implementation method is to layer embodied reasoning capabilities onto large multimodal LLMs, not to overturn the generative paradigm.
The logic: LLMs have already accumulated a compressed representation of thousands of years of human written knowledge. Layering visual, spatial perception, and reinforcement learning onto this foundation is more pragmatic than building a new architecture from scratch. Gemini Robotics and GPT-4o's multimodal capabilities exemplify this direction.
A practical supporting argument for this path: LLMs are already strong enough at common-sense reasoning, language instruction understanding, and cross-task generalization—precisely the weaknesses of pure RSSM/JEPA architectures. Gemini Robotics' approach: no need to build physical intuition from zero; directly leverage the "world common sense" already compressed in LLMs, then teach the model to map these to continuous physical actions.
But critics of this path have specific counterarguments: LLMs learn statistical correlations, not causal structures. It can tell you "a glass will break if dropped," but doesn't know why it breaks, into how many pieces, or where the fragments will bounce. This "knows the outcome but not the mechanism" understanding is sufficient for language tasks, but in robot manipulation, it might hit the hardest part: you need precise physical prediction, not just common sense.
Voice 3: The Direction Might Be Right, but the Timing Isn't Yet
This is currently the least publicly discussed but privately most widely circulated judgment in industry.
The core issue is data density: each language token carries extremely high semantic density; a single sentence conveys a complete proposition. Visual signals are different: one 1080p frame contains about 6 million pixels, but the propositional information it carries (who, where, doing what) compressed into text is only a few dozen words. With the same data volume, visual signals convey far less semantic information: low semantic density means more frames are needed to learn the same proposition. World models precisely require massive visual input, meaning the data volume and compute needed to train a world model with capabilities comparable to current LLMs might be several orders of magnitude higher, yet the resulting capabilities might not even match an early BERT.
History offers more than one cautionary tale: NLP research on syntax trees, dependency parsing, and part-of-speech tagging spanning decades was largely invalidated after LLMs emerged. The researchers weren't on the wrong path; they were run over by scaling laws ("The Bitter Lesson," Sutton, 2019). Spiking Neural Networks (SNNs), which most closely mimic biological neurons, were researched for nearly half a century, only to be leapfrogged by Transformers on nearly every benchmark, with no chance to catch up.
Those holding this view don't oppose the direction of world models; they oppose large-scale betting now. Until there's a fundamental breakthrough in the visual data density problem, the required objective functions, computational scale, and data volume are still far insufficient. This question mark deserves consideration by anyone seriously contemplating "should we bet on world models."
The three voices are not mutually exclusive. LeCun and Xie Saining are betting their funding and careers on the direction; DeepMind is approaching the same goal via engineering; skeptics are asking "even if the direction is right, are current conditions sufficient?" All three are real questions: the direction has entered the mainstream, but the outcome is not yet decided.
Conclusion
From Craik writing about "the small model in the skull" in 1943 to DreamDojo teaching robots to screw bolts from human videos in 2026, this thread has spanned 80 years, always pointing to the same question: How can an agent think things through before acting?
LLMs answer "what the world is like"; world models answer "what will happen to the world if I do this." These are two different problems, and currently, no single architecture has solved both well.
As robots and embodied intelligence move from labs to reality, the second question will become increasingly important.
If you're interested in this technical path and want to start from scratch—implementing everything from VAE encoders to a complete Dreamer pipeline—Datawhale is creating an open-source course and code to accompany it👇:
github.com/datawhalechina/learn-world-model
Feel free to star, fork, and contribute.

Loading...