Claude Opus 4.8 発表:SWE-Bench Pro 69.2%、GPT-5.5に10.6ポイント差 — Anthropicが示す「エージェント品質」の新基準

Anthropicは2026年5月28日、フラッグシップモデルの最新版「Claude Opus 4.8」を正式公開した。前モデルOpus 4.7からわずか6週間後のリリースであり、価格は据え置き。エージェントコーディング、推論、コンピュータ利用の各ベンチマークでOpenAI GPT-5.5およびGoogle Gemini 3.1 Proを上回る結果を示した。
ベンチマークが示す圧倒的差異
Opus 4.8の性能を端的に示すのが数字だ。
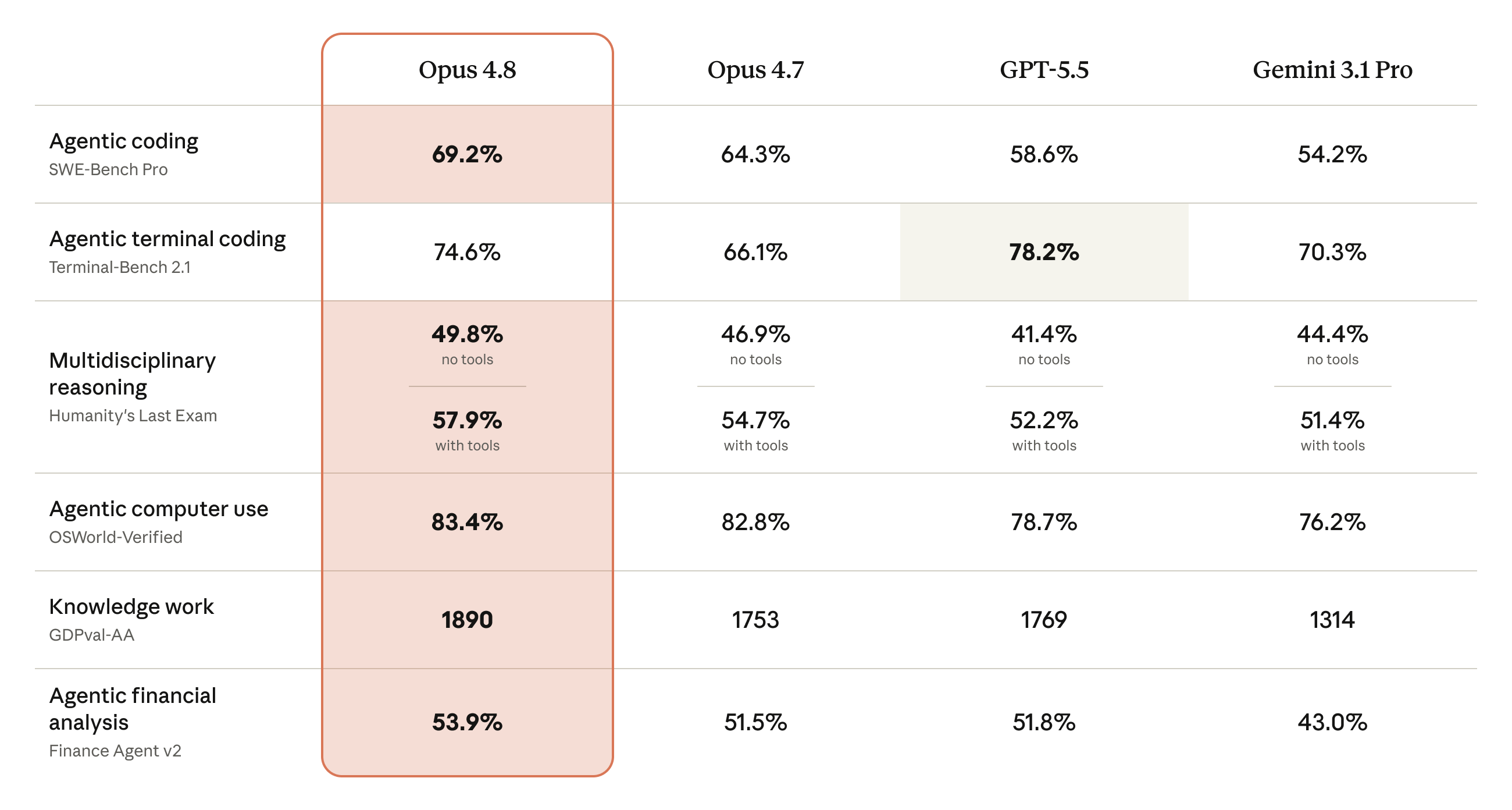
エージェントコーディング:SWE-Bench Pro
| モデル | スコア |
|---|---|
| Claude Opus 4.8 | 69.2% |
| Claude Opus 4.7 | 64.3% |
| GPT-5.5 | 58.6% |
| Gemini 3.1 Pro | 54.2% |
前モデルから4.9ポイントの改善。GPT-5.5に対しては10.6ポイントの差がある。SWE-Bench Proは実際のソフトウェアエンジニアリング課題を解かせるベンチマークであり、単なるコード生成ではなく「エージェントとして自律的に課題を解決する能力」を測定する。
多角的推論:Humanity's Last Exam
| モデル | ツールなし | ツールあり |
|---|---|---|
| Claude Opus 4.8 | 49.8% | 57.9% |
| GPT-5.5 | — | 52.2% |
| Gemini 3.1 Pro | — | 51.4% |
Humanity's Last Examは数学、科学、人文を横断する難問セットであり、ツール利用ありの設定でGPT-5.5に5.7ポイント差をつけている。
コンピュータ利用:OSWorld-Verified
| モデル | スコア |
|---|---|
| Claude Opus 4.8 | 83.4% |
| Claude Opus 4.7 | 82.3% |
| GPT-5.5 | 78.7% |
| Gemini 3.1 Pro | 76.2% |
ブラウザエージェントの評価であるOnline-Mind2Webでは84%を記録し、Opus 4.7とGPT-5.5の両方を上回った。
知識労働:GDPval-AA
| モデル | スコア |
|---|---|
| Claude Opus 4.8 | 1890 |
| GPT-5.5 | 1769 |
| Claude Opus 4.7 | 1753 |
唯一の逆転:Terminal-Bench 2.1
| モデル | スコア |
|---|---|
| GPT-5.5 | 78.2% |
| Claude Opus 4.8 | 74.6% |
| Gemini 3.1 Pro | 70.3% |
| Claude Opus 4.7 | 66.1% |
ターミナルコーディングのみGPT-5.5が3.6ポイントリードしている。ただしOpus 4.7から8.5ポイントの改善であり、差は縮小傾向にある。
「4倍正確」コード品質の進化
ベンチマークの数字以上に注目すべきは、コード品質の質的変化だ。AnthropicはOpus 4.8が「Opus 4.7と比較して、生成したコードの欠陥を見逃さない確率が約4倍」と報告している。
これは単にコードを正しく書く能力ではなく、自己検証能力の向上を意味する。具体的には:
- 自身のコードに潜むバグを指摘する頻度が大幅に増加
- 問題のある計画に対して異議を唱える傾向が強化
- 不確実性を認識し、明確に伝える能力が向上
- 根拠のない主張を行う頻度が減少
Cursor CEOのMichael Truellは「CursorBenchで、すべてのエフォートレベルにおいて既存のOpusモデルを上回った。ツール呼び出しもより効率的で、同等の知性をより少ないステップで実現している」と述べている。
Cognition CEOのScott Wuは「Opus 4.7で見られたコメント過多とツール呼び出しの問題を修正し、ツール使用がよりクリーンになった」と評価する。
価格とFast Mode
| モデル | 入力 | 出力 |
|---|---|---|
| Claude Opus 4.8(標準) | $5/MTok | $25/MTok |
| Claude Opus 4.8(Fast Mode) | $10/MTok | $50/MTok |
| Claude Opus 4.7 | $5/MTok | $25/MTok |
標準モードの価格はOpus 4.7と同一。Fast Modeは従来のFast Modeと比較して2.5倍の速度と3分の1のコストを実現している。Claude Codeでは/fastコマンドで即座に切り替え可能だ。
DatabricksのCTO Hanlin Tangは、実運用でのコスト削減効果について「Opus 4.7と比較してトークンコストが61%削減された」と報告している。これはFast Modeの単純な価格差ではなく、エージェントの効率改善による総合的な削減効果と考えられる。
Dynamic Workflows:数百の並列サブエージェント
Opus 4.8と同時に発表されたのが、Claude Codeの新機能「Dynamic Workflows」だ。Enterprise、Team、Maxプランでリサーチプレビューとして提供される。
この機能は、Claudeがタスクを計画し、単一のセッション内で数百の並列サブエージェントを起動して実行する。特徴的なのは:
- コードベース規模のマイグレーション:数十万行に及ぶコードベースの変更を、計画からマージまで一気通貫で実行
- 出力の自動検証:結果を報告する前に各サブエージェントの出力を検証
- テストスイート品質基盤:既存のテストスイートを品質基準として活用
ShopifyのStaff Engineer Tom Pritchardは「明らかに判断力が向上しており、複雑なマルチサービス探索において自信を構築していく様子が見られる」と評価する。
Messages APIの更新
開発者向けの重要な変更点として、Messages APIの改善がある。システムエントリーをmessages配列内に配置できるようになったことで、タスク実行中にClaudeの指示を更新できるようになった。プロンプトキャッシュを破壊することなく、ユーザーターンを経由せずに権限、トークン予算、環境コンテキストを動的に変更可能だ。
これは長時間実行されるエージェントタスクにおいて、柔軟性を大幅に向上させる。
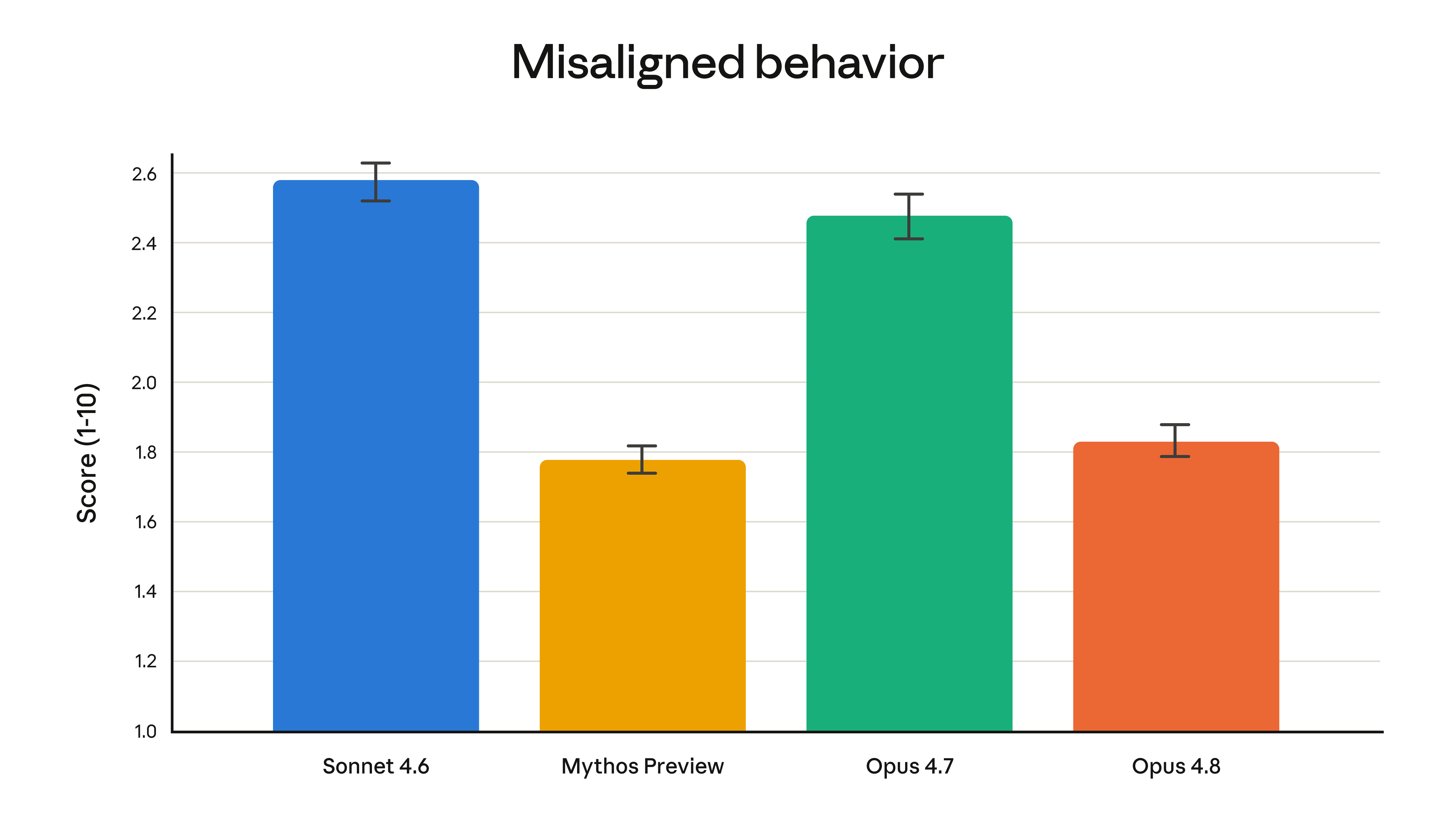
整合性の改善
| モデル | 不整合スコア |
|---|---|
| Claude Opus 4.8 | 約1.83 |
| Claude Opus 4.7 | 2.47 |
数値が低いほど望ましい。Opus 4.8の1.83は、Anthropicが最も整合性が高いと位置づけるMythos Previewと同等の水準にある。これは「支援的態度」「ユーザーの自律性の尊重」「社会的に望ましい特性」の総合評価であり、人間の監視なしに自律的に動作するエージェントにとって重要な指標となる。
エコシステムテスト結果
Opus 4.8は発表前から複数の主要企業によるテストが行われていた。
| 企業 | 評価 |
|---|---|
| Databricks | エージェント推論のステップチェンジ。Genieエージェントでトークンコスト61%削減 |
| Thomson Reuters | CoCounsel Legalワークフローの一貫性と推論品質が向上 |
| Hebbia | 引用精度とトークン効率が改善。大量の財務文書書処理で顕著な差 |
| Cursor | CursorBenchの全エフォートレベルで既存モデルを上回る |
| Shopify | 複雑なマルチサービス探索での判断力が向上 |
Effort Controlと今後の展望
claude.aiおよびCoworkでは、モデル選択肢の横に新しい「エフォートコントロール」が追加された。高エフォートほど深い推論と高品質な応答を、低エフォートほど高速な応答とレート制限の消費節約を実現する。全プランで利用可能だ。
また、Anthropicは次世代モデル「Claude Mythos」(Project Glasswing)についても言及している。Opusを超える知性を持つモデルクラスであり、現在Amazon、Microsoft、Appleが限定テスト中だ。サイバーセキュリティ特化の用途を想定しており、より強力な安全基準を満たした上で「今後数週間以内」に全顧客向けに展開予定とされる。
まとめと展望
Claude Opus 4.8は、数値上の改善だけでなく「エージェントとして信頼できるか」という問いに対するAnthropicの答えだ。SWE-Bench Pro 69.2%、OSWorld-Verified 83.4%、Humanity's Last Exam 57.9%。いずれもGPT-5.5を上回り、前モデルからの改善幅も大きい。
しかし、Terminal-Bench 2.1でGPT-5.5に逆転されている事実は、特定領域での優位性は確定的ではないことを示している。加速度的に変化する競争環境において、Opus 4.8は2026年5月時点での最有力候補ではあるが、その座は永続的なものではない。
真の差別化要因は、Dynamic Workflowsに代表される「数百のサブエージェントを統率する能力」と、整合性スコア1.83に示される「安全かつ信頼性の高い自律動作」にある。単独のタスクを正確にこなすモデルから、複雑なプロジェクトを自律的に遂行するエージェントへ。Opus 4.8はその転換点を明確に示したモデルと言える。

- 公式発表: [Introducing Claude Opus 4.8 — Anthropic](https://www.anthropic.com/news/claude-opus-4-8)
- 製品ページ: [Claude Opus 4.8 — Anthropic](https://www.anthropic.com/claude/opus)
- APIドキュメント: Pricing — Claude API Docs
関連記事
- [Claude Opus 4.8実測:作業能力は向上も、コミュニケーションに課題](/blog/claude-opus-48)
- [OpenAIが「GPT-5.5(コードネーム:Spud)」をリリース:エージェント能力が大幅向上、API提供は安全審査のため順次開始へ](/blog/openai-gpt-5-5-spud-release)
- SWE-bench Verified 2026最新ランキング:90モデルのコーディング性能を徹底比較
読み込み中...