Qwen3.7完全ガイド:Max・Plusの性能・料金・API利用法を徹底解説
Qwen3.7とは何か
2026年5月20日、アリババは阿里雲サミットで「Qwen3.7-Max」を正式発表した。エージェント時代の基盤モデルとして設計されたこのモデルは、単なる対話AIではなく、コードの記述・デバッグ、オフィスワークフローの自動化、数百から数千ステップに及ぶ長時間タスクの自律実行を目的としている。
Qwen3.7シリーズには2つのモデルが存在する。
| モデル | 定位 | 提供形態 |
|---|---|---|
| Qwen3.7-Max | 旗舰版。最強のエージェント能力 | API提供(閉源) |
| Qwen3.7-Plus | 高性能版。バランス型 | API提供(閉源) |
Qwen3.7-Maxはオープンソースではない。アリババは直近でQwen3.6-27B(Apache 2.0)やQwen3.6-35B-A3Bをオープンソースとしているが、3.7シリーズは現時点でAPI経由でのみ利用可能だ。
Arena AIランキングでの成績
Qwen3.7-Max-Previewは2026年5月19日にArena AI(旧LMArena)に登場し、即座に注目を集めた。
テキスト総合ランキング:第13位(GPT 5.5とGrok 4.2の間)、国产モデル第1位
視覚ランキング:Qwen3.7-Plus-Previewが第16位
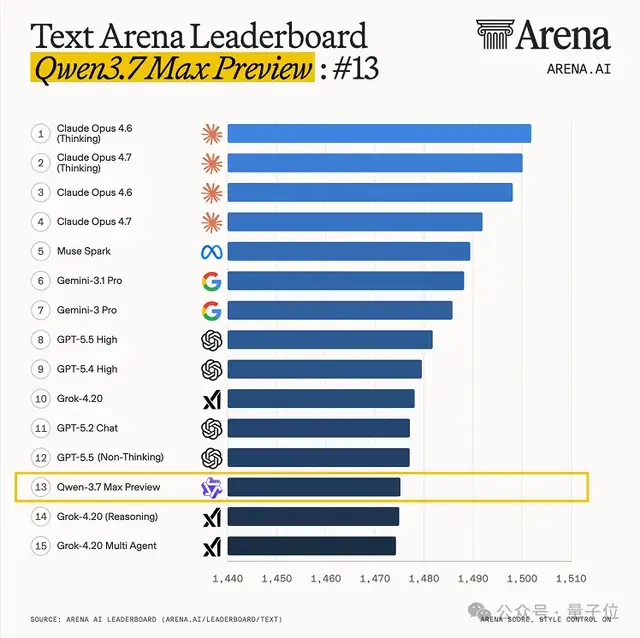
第三者評価機関Artificial Analysisの最新ランキングでは、Qwen3.7-Maxは総合スコア56.6を記録。GPT、Claude、Geminiの最强モデルに迫るスコアで、国产モデル第1位、世界第5位にランクインした。
ベンチマーク詳細スコア
BenchLM総合評価
BenchLM.aiの評価によると、Qwen3.7-Maxは総合スコア92/100で全117モデル中第3位。Arena Eloは1475。
| カテゴリ | スコア | ランキング |
|---|---|---|
| コーディング | 92.2 | #4 |
| 推論 | 96.4 | — |
| エージェント | 87.7 | — |
| 知識 | 86.8 | #9 |
| マルチリンガル | 88.2 | #10 |
| 指示追従 | 93.6 | #7 |
Arena Elo内訳
| カテゴリ | Elo | 投票数 |
|---|---|---|
| テキスト総合 | 1475 | 3,741 |
| コーディング | 1525 | 1,135 |
| 数学 | 1499 | 218 |
| ハードプロンプト | 1496 | 2,546 |
| マルチターン | 1484 | 648 |
主要ベンチマーク:他モデルとの比較
プログラミングエージェント
| ベンチマーク | Qwen3.7-Max | Claude Opus 4.6 | DeepSeek V4 Pro | GPT-5.5 |
|---|---|---|---|---|
| SWE-Pro | 60.6 | — | — | — |
| SWE-Multilingual | 78.3 | — | — | — |
| SWE-Verified | 80.4 | 80.8 | 80.6 | — |
| Terminal-Bench 2.0 | 69.7 | — | 67.9 | — |
| SciCode | 53.5 | — | — | — |
| NL2Repo | — | — | — | — |
SWE-VerifiedではClaude Opus 4.6 Max(80.8)やDeepSeek V4 Pro Max(80.6)とほぼ同スコア。Terminal-Bench 2.0ではDeepSeek V4 Pro Max(67.9)を上回った。
汎用エージェント
| ベンチマーク | Qwen3.7-Max | Claude Opus 4.6 | GLM 5.1 | Kimi K2.6 |
|---|---|---|---|---|
| MCP-Mark | 60.8 | — | 57.5 | — |
| MCP-Atlas | 76.4 | 75.8 | — | — |
| SkillsBench | 59.2 | — | — | 56.2 |
| BFCL-V4 | 75.0 | — | — | — |
| SpreadSheetBench-v1 | 87.0 | — | — | — |
| Kernel Bench L3 | 1.98x / 96% | — | — | — |
MCP-AtlasではClaude Opus 4.6(75.8)を僅差で上回り、SkillsBenchではKimi K2.6(56.2)を凌駕した。
推論能力
| ベンチマーク | Qwen3.7-Max | Claude Opus 4.6 | DeepSeek V4 Pro |
|---|---|---|---|
| GPQA Diamond | 92.4 | 91.3 | — |
| HLE | 41.4 | 40.0 | — |
| HMMT 2026 Feb | 97.1 | 96.2 | — |
| IMOAnswerBench | 90.0 | — | 89.8 |
| Apex | 44.5 | — | 38.3 |
推論ベンチマークではClaude Opus 4.6を一貫して上回る結果を示している。GPQA Diamond 92.4は、公開されているスコアの中ではトップクラスだ。
一般能力・マルチリンガル
| ベンチマーク | Qwen3.7-Max | DeepSeek V4 Pro |
|---|---|---|
| IFBench | 79.1 | 77.0 |
| WMT24++ | 85.8 | — |
| MAXIFE | 89.2 | — |
| SuperGPQA | 73.6 | — |
35時間の自律実験:最も重要な成果
ベンチマークスコア以上に注目すべきは、Qwen3.7-Maxが35時間に及ぶ完全自律的なタスクを成功させたという事実だ。
実験内容
アリババはQwen3.7-Maxに、トレーニング時に一度も见过ことのないチップ(平頭哥真武M890)上で推論カーネルを最適化させた。モデルにはハードウェアのドキュメントもプロファイリングデータも与えられなかった。タスクの説明、既存のSGLang実装、評価スクリプトだけが渡された。
結果
- 作業時間: 35時間連続(人間の介入なし)
- ツール呼び出し: 1,158回
- カーネル評価: 432回
- 最終結果: Triton参照実装比10.0倍の幾何平均加速
モデルは35時間の間、一貫した推論戦略を維持し続けた。30時間経過後も有意な改善を発見し続けており、長時間の自律的最適化が「実現可能」であるだけでなく「生産的」であることを示した。
他モデルとの比較
| モデル | 幾何平均加速比 | 備考 |
|---|---|---|
| Qwen3.7-Max | 10.0x | 35時間完走 |
| GLM 5.1 | 7.3x | — |
| Kimi K2.6 | 5.0x | — |
| DeepSeek V4 Pro | 3.3x | 途中中断 |
| Qwen3.6-Plus | 1.1x | 途中中断 |
途中中断したモデルは「5ラウンド連続でツール呼び出しがなかった」場合に自動終了している。つまり、モデル自身が「これ以上改善できない」と判断して作業を停止したのだ。
KernelBench L3での結果
同じくカーネル生成能力を測るKernelBench L3では、Qwen3.7-Maxは96%のシナリオで加速カーネルを生成。比較対象は以下の通り。
| モデル | 加速カーネル生成率 |
|---|---|
| Claude Opus 4.6 | 98% |
| Qwen3.7-Max | 96% |
| GLM 5.1 | 78% |
| Kimi K2.6 | 80% |
| DeepSeek V4 Pro | 54% |
YC-Bench:スタートアップ経営シミュレーション
Qwen3.7-Maxの另一个注目すべき成果は、YC-Benchでの成績だ。このベンチマークはスタートアップの1年間のライフサイクル全体をシミュレーションし、人員管理、契約審査、悪意あるクライアントの識別など、数百回の意思決定を要求する。
| モデル | 総収益 | 完了タスク数 |
|---|---|---|
| Qwen3.7-Max | 2.08M USD | 237 |
| Qwen3.6-Plus | 1.05M USD | — |
| Qwen3.5-Plus | 352K USD | — |
Qwen3.7-Maxは前世代の約2倍、3.5世代の約6倍の収益を達成した。
API料金
Qwen3.7-MaxはアリババクラウドのModel Studio経由で提供される。
| 項目 | 料金 |
|---|---|
| 入力トークン | $2.50 / 1Mトークン |
| 出力トークン | $7.50 / 1Mトークン |
| コンテキストウィンドウ | 1Mトークン |
比較的安価な料金設定だ。Claude Opus 4.6の入力$15/出力$75と比べると、入力は約1/6、出力は約1/10の価格となっている。
API利用方法
OpenAI互換API
Qwen3.7-MaxはOpenAI互換のAPIプロトコルをサポートしている。
from openai import OpenAI
client = OpenAI(
api_key="your-dashscope-api-key",
base_url="https://dashscope-intl.aliyuncs.com/compatible-mode/v1"
)
completion = client.chat.completions.create(
model="qwen3.7-max",
messages=[{"role": "user", "content": "Pythonでソート済み連結リストをマージする関数を書いて"}],
extra_body={"enable_thinking": True},
stream=True
)
Claude Codeとの統合
Qwen APIはAnthropic APIプロトコルもサポートしており、Claude Codeに直接接続できる。
export ANTHROPIC_MODEL="qwen3.7-max"
export ANTHROPIC_SMALL_FAST_MODEL="qwen3.7-max"
export ANTHROPIC_BASE_URL=https://dashscope-intl.aliyuncs.com/apps/anthropic
export ANTHROPIC_AUTH_TOKEN=<your_api_key>
claude
OpenClawとの統合
curl -fsSL https://molt.bot/install.sh | bash
export DASHSCOPE_API_KEY=<your_api_key>
openclaw dashboard
Qwen Code
npm install -g @qwen-code/qwen-code@latest
qwen
preserve_thinking機能
Qwen3.7-Maxはpreserve_thinking機能をサポートしている。これはエージェントタスクに推奨される機能で、メッセージ内の先行ターン全ての思考内容を保持する。長時間のマルチターン対話において、モデルの推論の一貫性を維持するのに役立つ。
Qwenシリーズの迭代ペース
Qwen3.7-Maxは、3ヶ月連続での旗舰モデルリリースという異例のペースの中で登場した。
| 日付 | モデル | テーマ |
|---|---|---|
| 2026年2月 | Qwen3.5-Max | 原生マルチモーダルエージェント |
| 2026年3月30日 | Qwen3.5-Omni | 全モーダル対応 |
| 2026年4月2日 | Qwen3.6-Plus | エージェントプログラミング強化 |
| 2026年4月16日 | Qwen3.6-35B-A3B | MoEオープンソース |
| 2026年4月22日 | Qwen3.6-27B | 稠密モデルオープンソース |
| 2026年5月20日 | Qwen3.7-Max | エージェント時代の新基準 |
毎月1世代の旗舰モデルをリリースし、そのたびに国产モデルの性能上限を更新している。この反復速度は、業界でも類を見ないペースだ。
他のQwen3.7クエリについて
Qwen3.7-Plus
Qwen3.7-PlusはMaxの弟分的存在で、視覚能力に強みを持つ。Arena AIの視覚ランキングで第16位を記録している。Maxと同様に思考モードをサポートするが、コストパフォーマンスに優れた選択肢となる。
Qwen3.7-Preview
Qwen3.7-Max-PreviewとQwen3.7-Plus-Previewは、正式リリース前のプレビュー版として2026年5月19日にArena AIに登場した。現時点では思考モードのみ対応で、検索機能やコードインタープリターはまだ開放されていない。
Qwen3.7-Max vs Qwen3.6-Plus
Qwen3.6-Plusは2026年4月2日にリリースされたモデルで、Qwen3.7-Maxの直接的な前任者にあたる。3.7-Maxは3.6-Plusと比較して、エージェント能力、推論精度、長時間タスク実行の安定性で大幅な改善を実現している。YC-Benchの収益比較(2.08M vs 1.05M)がその差を端的に示している。
まとめ
Qwen3.7-Maxは、エージェント能力に特化したアリババの最新旗舰モデルだ。主要ベンチマークでClaude Opus 4.6やDeepSeek V4 Proに匹敵または上回る性能を示し、35時間の自律実験では10倍の性能向上を達成した。
ポイントを整理すると:
- Arena総合国产第1位、世界第5位
- 推論能力: GPQA Diamond 92.4でClaude Opus 4.6(91.3)を上回る
- コーディング: SWE-Pro 60.6、Terminal-Bench 69.7
- 35時間自律実験: 1,158回のツール呼び出しで10倍加速
- 料金: 入力$2.50/出力$7.50 per 1Mトークン(Claude比で約1/10)
- コンテキスト: 1Mトークン
- 統合: Claude Code、OpenClaw、Qwen Codeに対応
エージェント時代の基盤モデルとして、Qwen3.7-Maxは「賢い」だけでなく「長時間働き続けられる」という点で新しい基準を打ち出している。
関連記事
- Qwen3.7-Max発表:35時間の自律的カーネル最適化で推論性能が10倍に
- 【2026年5月版】主要AIモデルAPI料金の完全比較一覧
- [OpenAIが「GPT-5.5(コードネーム:Spud)」をリリース:エージェント能力が大幅向上、API提供は安全審査のため順次開始へ](/blog/openai-gpt-5-5-spud-release)
読み込み中...